Mi cerebro digital: cómo conecté memoria, conocimiento y publicación automática
Cómo construí un sistema que extrae memorias de IA desde un VPS, las organiza en Obsidian al estilo Karpathy, y publica artículos automáticamente en el blog, X.com y LinkedIn.
Mario Inostroza
Hace seis meses, cada vez que terminaba una sesión de trabajo con Claude, el conocimiento acumulado desaparecía. Las decisiones de arquitectura, los bugs resueltos a las 2am, los patrones que descubrí depurando un API de terceros — todo se perdía en el vacío de contextos efímeros. Hoy, tengo un sistema que recuerda por mí, organiza ese conocimiento automáticamente, y cuando decido compartirlo, lo publica en tres plataformas sin que yo toque un botón.
Le llamo mi cerebro digital.
El problema: dos cerebros que no se hablaban
Trabajo en dos frentes simultáneos. En mi Mac, sesiones de diseño y escritura con Claude Cowork. En mi VPS (srv788271), un agente llamado Cotocha (OpenClaw) ejecuta tareas técnicas: código, despliegues, debugging nocturno de Examya.
Cada uno acumulaba conocimiento en silos separados. Cotocha sabía sobre los errores de configuración del servidor. Mi Mac sabía sobre las decisiones de producto. Ninguno conocía el trabajo del otro. El resultado era un sistema de memoria parcialmente amnésico.
El segundo problema era la publicación. Tenía ideas, tenía contexto, pero el camino desde “pensé algo interesante” hasta “está publicado en el blog y tuiteado” involucraba demasiados pasos manuales.
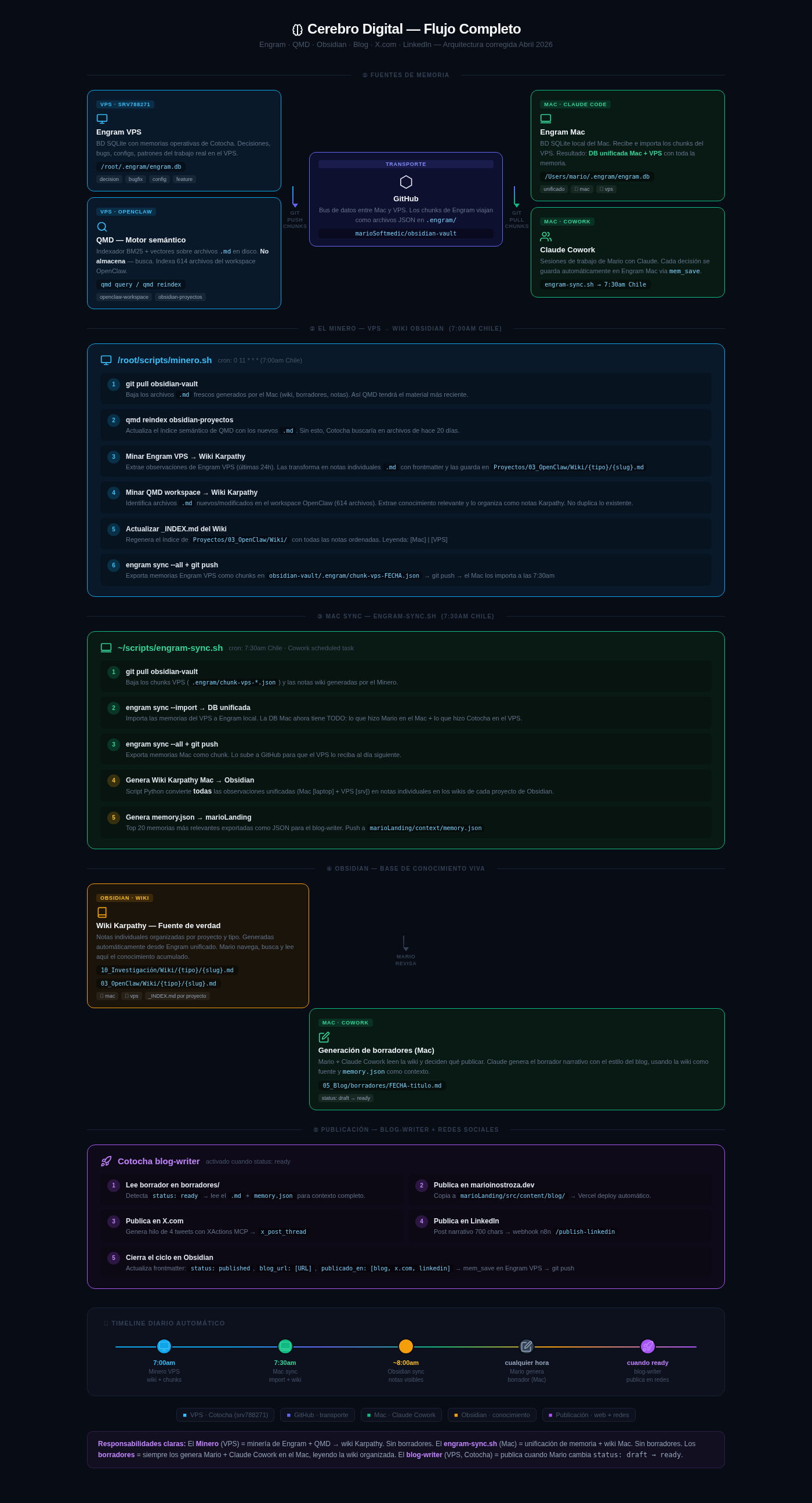
La arquitectura: cuatro capas que se alimentan entre sí
Después de semanas de iteración, llegué a un sistema de cuatro capas.
Capa 1: Fuentes de memoria
Engram es la pieza central. Es una base de datos SQLite que almacena observaciones estructuradas: cada decisión importante, cada bug resuelto, cada patrón identificado queda registrado con metadatos (tipo, proyecto, topic_key, fuente). Corro una instancia en el VPS (/root/.engram/engram.db) y otra en el Mac (/Users/mario/.engram/engram.db).
QMD (OpenClaw) complementa a Engram desde el ángulo opuesto. No almacena — indexa. Es un motor semántico BM25 + vectores que indexa los 614 archivos .md del workspace de OpenClaw. Cuando Cotocha necesita contexto sobre un tema, qmd query "patrón X" devuelve los fragmentos más relevantes de toda la base de conocimiento existente.
Capa 2: El Minero — automatización nocturna en el VPS
Cada mañana a las 7:00am (Chile), un cron ejecuta /root/scripts/minero.sh. Este script hace algo simple pero poderoso:
- Baja los últimos archivos del vault de Obsidian desde GitHub
- Reindexa QMD con el material nuevo
- Extrae las observaciones de Engram VPS de las últimas 24 horas
- Transforma cada observación en una nota
.mdindividual con frontmatter — el formato que describe Andrej Karpathy para una wiki personal - Identifica archivos nuevos en el workspace OpenClaw y extrae conocimiento relevante
- Empuja todo a GitHub: las notas wiki y los chunks de memoria exportados
El resultado: Cotocha “recuerda” lo que hizo ayer, y ese conocimiento se convierte automáticamente en estructura navegable.
Capa 3: Sincronización Mac — base unificada
A las 7:30am, engram-sync.sh en el Mac recoge lo que dejó el Minero:
- Importa los chunks de Engram VPS a la base de datos Mac → DB unificada Mac + VPS
- Genera la wiki Karpathy local: convierte todas las observaciones (Mac + VPS) en notas individuales en el vault de Obsidian
- Exporta
memory.json: las top 20 memorias más relevantes como contexto para el blog-writer
Para las 8:00am, el vault de Obsidian tiene conocimiento actualizado de ambos sistemas. GitHub actúa como bus de datos — los chunks de Engram viajan como archivos JSON en .engram/ del repositorio marioSoftmedic/obsidian-vault.
Capa 4: Publicación — de borrador a tres plataformas
Cuando quiero publicar algo, Mario + Claude Cowork leemos la wiki y generamos un borrador narrativo en 05_Blog/borradores/. El borrador vive en Obsidian con status: draft.
Cuando cambio el frontmatter a status: ready, Cotocha detecta el cambio y ejecuta el blog-writer skill:
- Lee el borrador completo más
memory.jsonpara contexto - Copia el artículo a
marioLanding/src/content/blog/→ deploy automático en Vercel - Genera un hilo de 4 tweets con XActions MCP (
x_post_thread) — sin API keys, usa browser auth token - Publica un post narrativo de 700 chars en LinkedIn vía webhook n8n (
/publish-linkedin) con OAuth2 nativo - Cierra el ciclo: actualiza el frontmatter con
status: published,blog_url,publicado_en: [blog, x.com, linkedin]y hacemem_saveen Engram VPS
Las herramientas que lo hacen posible
El stack completo son herramientas open source o de bajo costo:
- Engram (mem_save MCP): memoria persistente con protocolo MCP
- QMD: motor semántico BM25+vectores corriendo en el VPS
- Obsidian: vault local sincronizado con GitHub, formato wiki estilo Karpathy
- XActions MCP (nirholas/XActions): 140+ herramientas de X.com sin API keys
- n8n: automatización con nodo nativo LinkedIn OAuth2
- Vercel: deploy automático del blog en cada push
- GitHub: bus de datos bidireccional Mac ↔ VPS
Lo que cambió en mi flujo de trabajo
El cambio más importante no es técnico — es cognitivo. Antes de Engram, tomaba decisiones de arquitectura y al día siguiente dudaba de por qué las había tomado. Ahora, cada decisión tiene un rastro. Puedo preguntarle a Cotocha “¿qué decidimos sobre el esquema de base de datos de Examya?” y recibir la observación exacta, con fecha, proyecto y razonamiento.
El segundo cambio es la compostura ante la publicación. El proceso de escribir un artículo ya no parte desde cero — parte desde la wiki. Leo los patrones que emergieron en las últimas semanas, identifico qué vale la pena compartir, y el borrador se genera sobre conocimiento real, no sobre recuerdos vagos.
Lo que sigue
Hay tres piezas que aún estoy ajustando:
LinkedIn OAuth2: La app marioinostroza-publisher está en configuración. Falta completar el flujo OAuth en n8n con la URL de ngrok de Cotocha. Una vez listo, el pipeline de publicación está completo.
Minero semántico QMD más profundo: Actualmente el Minero extrae por fecha. El siguiente paso es que use QMD para identificar patrones entre observaciones — conocimiento emergente que no está en ninguna nota individual pero se puede inferir del conjunto.
Wiki pública: Una selección curada de las notas Karpathy publicada en el blog como recurso de referencia. La versión personal de los “100 páginas de ML” de Karpathy, pero sobre sistemas de agentes.
Si estás construyendo algo similar o tienes preguntas sobre alguna pieza del stack, escríbeme. Este sistema nació de muchos intentos fallidos y las correcciones vinieron de conversaciones reales.
Lecturas relacionadas
En esta serie
Cotocha: el orquestador de agentes que corre mi vida desde un VPS
Cómo construí un sistema de agentes IA que maneja infraestructura, alertas, base de datos y blogging desde un servidor en Alemania. Sin intermediarios, sin dashboards bonitos.
En esta serie
Una semana de construcción: 82 decisiones que moldean un producto de IA
Lo que revelan las memorias de Engram sobre una semana real de desarrollo: bugs cazados, arquitectura endurecida, y las decisiones invisibles que hacen que un agente médico funcione.
En esta serie
Sincronización bidireccional Mac-VPS con Engram: el cerebro que nunca se apaga
Tutorial técnico de cómo construí un pipeline de sincronización bidireccional entre mi Mac, un VPS en Alemania, Engram, Obsidian y el método Karpathy de knowledge management. Todo con scripts Python, git y cron jobs.