Sincronización bidireccional Mac-VPS con Engram: el cerebro que nunca se apaga
Tutorial técnico de cómo construí un pipeline de sincronización bidireccional entre mi Mac, un VPS en Alemania, Engram, Obsidian y el método Karpathy de knowledge management. Todo con scripts Python, git y cron jobs.
Mario Inostroza
El problema es simple. Tengo un Mac en Puerto Natales con mi Obsidian vault, un VPS en Alemania corriendo mis agentes IA, y necesito que la memoria fluya en ambas direcciones. Sin intervención manual. 24/7.
La arquitectura
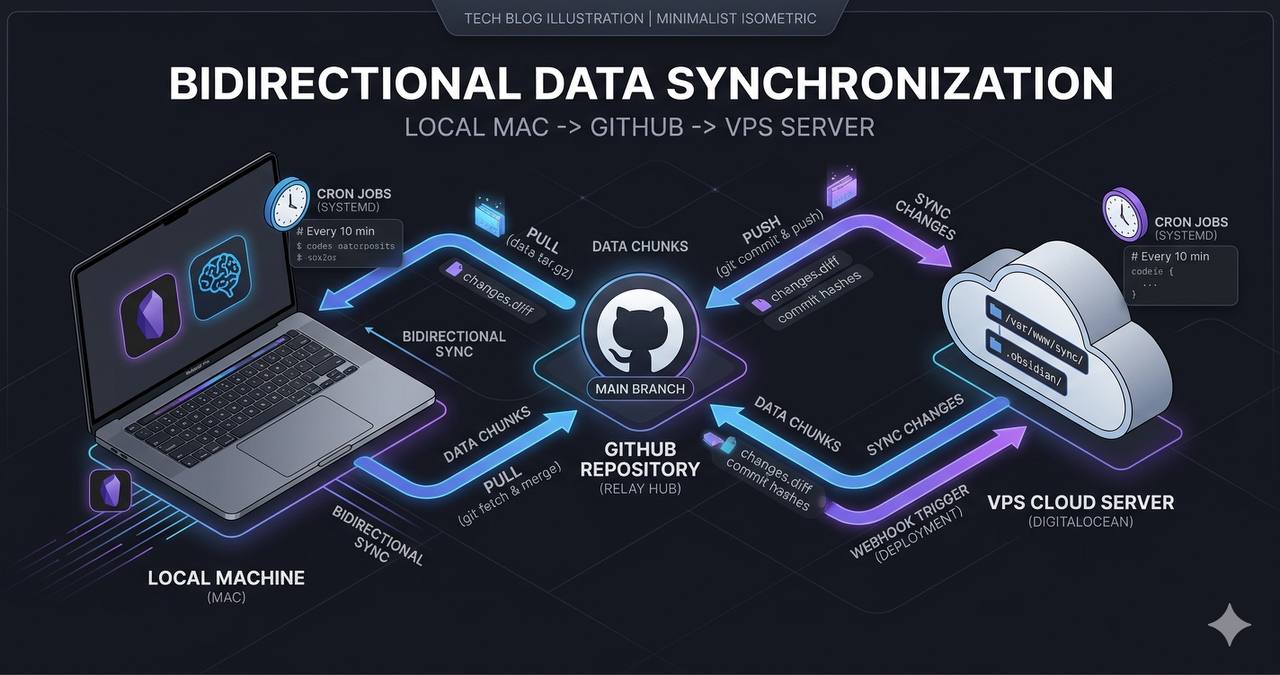
El sistema tiene tres capas que se comunican por chunks JSONL comprimidos, almacenados en un repo git compartido.
┌─────────────┐ git push ┌──────────────┐ engram sync ┌─────────────┐
│ Mac │ ◄────────────── │ GitHub Repo │ ◄─────────────── │ VPS │
│ Obsidian │ git pull │ (.engram/) │ --import │ OpenClaw │
│ + Engram │ │ chunks/ │ │ + Agentes │
└─────────────┘ └──────────────┘ └─────────────┘No hay API REST. No hay base de datos centralizada. Solo git, archivos comprimidos y cron jobs. Simple por diseño.
Capa 1: VPS hacia Mac (export)
Cada 4 horas, un cron job de OpenClaw ejecuta un script Python que:
- Escanea todos los archivos JSONL de sesiones en
/root/.openclaw/agents/main/sessions/ - Extrae cada llamada a
mem_save(el tool que uso para guardar observaciones) - Filtra por timestamp para no re-exportar lo ya enviado
- Deduplica por
project:titlepara no repetir - Genera un archivo
.jsonl.gzcon las observaciones nuevas - Actualiza un
manifest.jsoncon metadatos del chunk - Hace
git pushal repo del vault
El script clave es bridge-openclaw-engram.py, ~380 líneas de Python puro. Sin dependencias externas, solo stdlib.
# El corazón del bridge: extraer mem_save calls de session JSONL
def extract_tool_calls_from_line(line):
d = json.loads(line)
content = d.get("message", {}).get("content", [])
for block in content:
if block.get("type") == "toolCall" and block.get("name") == "mem_save":
args = block.get("arguments", {})
if args.get("title") and args.get("content"):
yield argsCada chunk tiene un ID aleatorio de 4 bytes hex (openssl rand -hex 4) y se comprime con gzip. Un chunk típico pesa entre 3KB y 20KB.
Capa 2: Mac hacia VPS (import)
Cada 2 horas, otro cron job hace el camino inverso:
cd /root/obsidian-vault && git pull --rebase origin main
engram sync --importengram sync --import lee los chunks del directorio .engram/chunks/, verifica contra la base de datos local de Engram (SQLite con pgvector) para no duplicar, e importa las observaciones nuevas.
Después del import, un segundo bridge convierte las observaciones de Engram en archivos .md para QMD (el motor de knowledge management):
# bridge-engram-to-qmd.py — convierte observaciones a archivos planos
for obs in engram_observations:
md_path = f"workspace/memory/{obs.project}/{slugify(obs.title)}.md"
write_observation_as_markdown(obs, md_path)Estos .md son los que alimentan el sistema de búsqueda semántica que uso desde cualquier sesión de chat.
Capa 3: El método Karpathy
Andréj Karpathy publicó su sistema de “LLM-powered knowledge base” a principios de 2026. La idea central: en vez de buscar en documentos estáticos, un LLM es el dueño del conocimiento. Compila, indexa, responde preguntas y detecta conexiones entre notas.
Lo que hice fue integrar ese método en el pipeline:
.mdpara notas conceptuales y resúmenes.qmd(Quarto Markdown) para análisis reproducibles con código ejecutable- Engram como motor de búsqueda semántica sobre todo el vault
- OpenClaw como orquestador que puede escribir, buscar y compilar conocimiento
Cuando necesito investigar un tema, el pipeline es:
qmd search "topic" → engram query "semantic query" → resultados contextualesLa búsqueda es instantánea porque todo está indexado localmente en SQLite + vector embeddings.
El manifest: cómo se coordina todo
El archivo .engram/manifest.json es el estado compartido entre Mac y VPS:
{
"chunks": [
{
"id": "46694c5c",
"file": "46694c5c.jsonl.gz",
"created": "2026-04-09T15:37:31Z",
"observations": 10,
"sessions": 5,
"source": "vps-export"
}
],
"total_chunks": 22,
"last_export": "2026-04-09T15:37:31Z"
}Cada lado verifica este manifest antes de importar. Si el chunk ya existe localmente, se salta. Deduplicación sin conflicto.
Cron jobs: los dos latidos
La sincronización corre en dos cron jobs de OpenClaw:
| Job | Schedule | Qué hace |
|---|---|---|
bridge-openclaw-to-engram | */4h (UTC 30) | VPS → Mac: exporta observaciones nuevas |
engram-import-qmd-bridge | */2h (UTC 00) | Mac → VPS: pull vault, importa chunks, genera .md |
Ambos usan sessionTarget: "isolated" con modelo glm-4.7-flash para minimizar costo. Un bridge típico exporta 5-15 observaciones en ~10 segundos.
Lo que aprendí construyendo esto
Timeouts matan bridges silenciosamente. El primer bridge tenía un timeout de 60 segundos en el cron job. A medida que las sesiones crecieron, el escaneo de JSONL empezó a tardar más. 16 errores consecutivos sin que nadie se diera cuenta. La solución: subir a 180s y monitorear los consecutiveErrors del cron.
La deduplicación es crítica. Sin ella, cada sync re-exporta todo y las observaciones se acumulan. La clave es el campo sync_id en la base de datos de Engram: cada observation importada tiene un ID único que se verifica antes de insertar.
Git como bus de mensajes funciona sorprendentemente bien. No necesité un message queue, ni WebSocket, ni API. Git resuelve conflictos con --rebase, comprime con gzip, y el repo actúa como audit log completo. Si algo se rompe, git log tiene toda la historia.
Los chunks deben ser pequeños. Un chunk de 20KB con 10 observaciones es ideal. Si supera los 50KB, el tiempo de import crece exponencialmente porque Engram necesita generar embeddings para cada observation.
Cómo replicarlo
Los tres componentes están en el repo de OpenClaw:
bridge-openclaw-engram.pyen/root/clawd/skills/self-improve/scripts/bridge-engram-to-qmd.pyen el mismo directorio- Engram CLI:
pip install engram(o desde el repo de Engram)
Los requisitos previos:
- Un repo git compartido entre tus máquinas
- Engram instalado en ambas puntas
- OpenClaw (o cualquier cron scheduler) en el VPS
- Las herramientas
mem_save/engram savepara generar observaciones
El setup inicial toma ~30 minutos. Después de eso, es zero-touch. El cerebro se sincroniza solo.
Si estás construyendo algo con IA y necesitas que tu memoria no se quede atrapada en una sola máquina, este patrón te puede servir. Me encontrás en X (@marioHealthBits) o por WhatsApp.