OCR médico en WhatsApp: cómo mi agente lee órdenes de exámenes y resultados de laboratorio
Arquitectura real del pipeline OCR de Examya: cómo un agente de IA clasifica fotos en WhatsApp, decide si son órdenes médicas o resultados de laboratorio, y genera cotizaciones FONASA automáticamente. Con bugs reales y decisiones de diseño explicadas.
Mario Inostroza
Un paciente saca una foto de su orden médica con el celular y la manda por WhatsApp. En menos de 10 segundos, recibe una cotización con precios FONASA y un link de pago. Sin call center. Sin formularios. Sin apps que instalar.
Esto es lo que pasa por dentro.
El problema que resuelve
En Chile, conseguir el precio de un examen de laboratorio es frustrante. Tenés que llamar, esperar, a veces ir en persona. Examya lo resuelve: el paciente manda la orden médica por WhatsApp y el sistema lee los exámenes, consulta el catálogo FONASA, y devuelve una cotización en segundos.
El mismo canal sirve para resultados: cuando el laboratorio tiene los resultados listos, el paciente manda la foto y el agente los interpreta, explica los valores, y alerta si algo está fuera de rango.
El desafío técnico: el agente necesita distinguir, en tiempo real, si la foto es una orden médica (para cotizar) o un resultado de laboratorio (para interpretar). Son flujos completamente distintos.
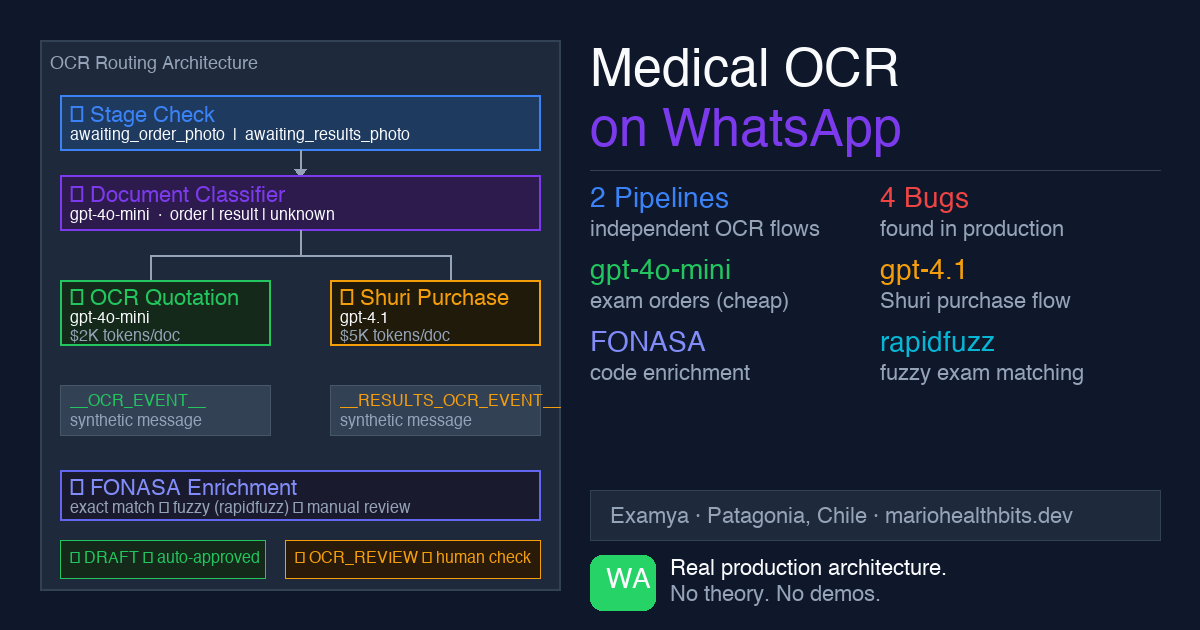
La arquitectura de ruteo
Todo empieza en el webhook controller. Cuando Meta envía un mensaje con media, handleMediaMessageFromBuffer() lo procesa antes de que Shuri (el agente conversacional) lo vea.
El flujo de decisión tiene tres capas:
Foto llega por WhatsApp
↓
¿stage == 'awaiting_results_photo'?
SÍ → handleResultsPhotoOcr() → ExamResultInterpreterAgent
↓ (si NO)
Document Classifier
'exam_result' → handleResultsPhotoOcr() → ExamResultInterpreterAgent
'medical_order' → OCR Quotation → enriquecimiento FONASA → link de pago
not_medical → "Eso no parece un documento médico"El stage tiene prioridad absoluta. Si el paciente está en awaiting_results_photo, la foto va directo a interpretación sin pasar por el classifier. El sistema ya sabe qué espera.
Si no hay stage activo, entra el document classifier. Acá hay una decisión deliberada: el classifier falla abierto como medical_order. Si no puede clasificar la imagen, asume orden médica y la manda a cotización. Prefiero cotizar algo que no era orden que intentar interpretar un resultado mal.
El bridge de eventos: cómo la foto llega al agente
Shuri no detecta media directamente. El webhook procesa la imagen, ejecuta el OCR, y después inyecta mensajes sintéticos en el agente:
__OCR_EVENT__:para órdenes médicas (cotización)__RESULTS_OCR_EVENT__:para resultados (interpretación)
El agente nunca ve la imagen. Ve un evento de texto con el resultado del OCR ya procesado. Esta separación mantiene a Shuri agnóstico del canal: el mismo agente podría recibir eventos de email, SMS, o cualquier otro canal sin cambiar su lógica interna.
Dos pipelines, dos modelos, dos precios
Los flujos de cotización e interpretación son completamente independientes.
OCR Quotation (orden médica):
- Modelo:
gpt-4o-mini(velocidad y costo) - Precio:
$2.000desdeWHATSAPP_QUOTE_PRICEenv var - Crea
MedicalOrderSaleconisQuotation: true - PDF: título “COTIZACIÓN DE EXÁMENES”, precios FONASA (Nacional 3 niveles / Magallanes nivel 3), sin sección de médico
Shuri Purchase (compra desde conversación de síntomas):
- Modelo:
gpt-4.1para el interpreter (precisión) - Precio:
$5.000desdeWHATSAPP_ORDER_PRICEenv var - Crea
MedicalOrderSaleconisQuotation: false - PDF: título “ORDEN MÉDICA”, con sección de médico, sin precios FONASA
La separación es intencional. Una cotización es informal; una orden médica tiene consecuencias legales. Los PDFs, precios y flujos son distintos por diseño.
El enriquecimiento FONASA
Después de que el OCR extrae los exámenes de la imagen, viene el mapeo al catálogo oficial de FONASA.
El problema: los médicos escriben los nombres de formas distintas. “Hemograma”, “hemograma completo”, “CBC”, “recuento sanguíneo completo” son el mismo examen. El OCR puede extraer cualquier variante.
El enriquecimiento usa dos estrategias en orden:
- Match exacto contra el catálogo (con normalización de tildes y mayúsculas)
- Fuzzy match con
rapidfuzzsi el exacto falla
Los exámenes que no matchean van al array enrichedResult.pending y se notifican al paciente: “Encontré estos exámenes pero no pude cotizarlos automáticamente”. No se descartan silenciosamente.
Los bugs que encontré en producción
Bug 1: precio hardcodeado. En dos lugares del controller había const FIXED_ORDER_PRICE = 2000 en vez de leer del env var. El PurchaseHandler leía correctamente de WHATSAPP_QUOTE_PRICE, pero el OCR flow no.
Bug 2: link de pago duplicado. El controller enviaba el link inline de forma síncrona, Y el Bull processor también lo enviaba ~48 segundos después. El paciente recibía dos links distintos para la misma orden. Fix: markPaymentLinkSent(orderId) en un Map de deduplicación en memoria con TTL de 5 minutos.
Bug 3: contaminación de isQuotation. Si el paciente cotizó antes (OCR flow, isQuotation: true) y después quiso comprar (Shuri Purchase), el contexto de sesión todavía tenía isQuotation: true. La orden de compra salía como cotización a $2.000. Fix: hardcodear isQuotation: false en PurchaseHandler. El flujo de compra nunca crea cotizaciones.
Bug 4: exámenes descartados silenciosamente. Al crear la orden desde pending OCR, los exámenes sin códigos FONASA válidos (/^\d{6,7}$/) se descartaban sin avisar. El paciente recibía una orden con menos exámenes de los que mandó.
El estado de calidad automático
Con el PR #349, el pipeline ahora evalúa su propia calidad antes de crear la orden.
OcrExtractionEvaluatorService analiza el resultado y devuelve ocrQualityPassed: boolean. Si la calidad es baja (imagen borrosa, pocos exámenes detectados), la orden entra en estado OCR_REVIEW y un operador la revisa antes de que llegue al paciente.
ocrQualityPassed === true → DRAFT → flujo normal
ocrQualityPassed === false → OCR_REVIEW → revisión humana
ocrQualityPassed === undefined → DRAFT → default seguroEsto evita que el paciente reciba una cotización con 0 exámenes porque la foto estaba movida.
El edge case que más dolió
Paciente en awaiting_results_photo (esperando mandar sus resultados de laboratorio). Por error, manda la foto de una orden médica nueva.
El sistema, por la regla de prioridad del stage, la trata como resultado. Responde: “No pude identificar valores en tu documento.” El stage se resetea a START. La cotización se pierde. El paciente empieza de cero.
Bug documentado, pendiente de fix. La solución correcta: si el stage dice awaiting_results_photo pero el classifier dice medical_order con alta confianza, preguntar al paciente cuál era su intención. Por ahora, el stage gana siempre.
Lo que viene
El exam normalizer está en 0% en el baseline actual porque no canonicaliza nombres contra el catálogo. Cuando el OCR devuelve “funcion hepatica”, el normalizer debería mapear automáticamente a “PERFIL HEPÁTICO” antes del enriquecimiento FONASA. Ese es el próximo fix.
El pipeline funciona. Lo que sigue es hacerlo más robusto contra imágenes de baja calidad y variantes de nombres menos comunes.
Si estás construyendo procesamiento de documentos médicos con IA y tenés preguntas sobre la arquitectura, me encontrás en X (@marioHealthBits) o por WhatsApp.
Lecturas relacionadas
En esta serie
Cómo instalé el primer lab PCR privado de Magallanes (y por qué terminé construyendo IA)
En marzo 2021, subí un gabinete de 300 kg con grúa al segundo piso en cuarentena patagónica. En mayo procesábamos los primeros PCR COVID privados de Magallanes. Lo que aprendí en esas noches me llevó a construir Examya.
En esta serie
Examya: cómo construí un agente médico para WhatsApp que procesa órdenes de exámenes
Detalles técnicos de la implementación del agente Shuri en Examya, un sistema para procesar órdenes médicas vía WhatsApp con integración FONASA.
En esta serie
pgvector + embeddings en producción: La base de razonamiento médico en Examya
Arquitectura de búsqueda semántica y similitud textual en producción con pgvector, pg_trgm y datos MINSAL reales.