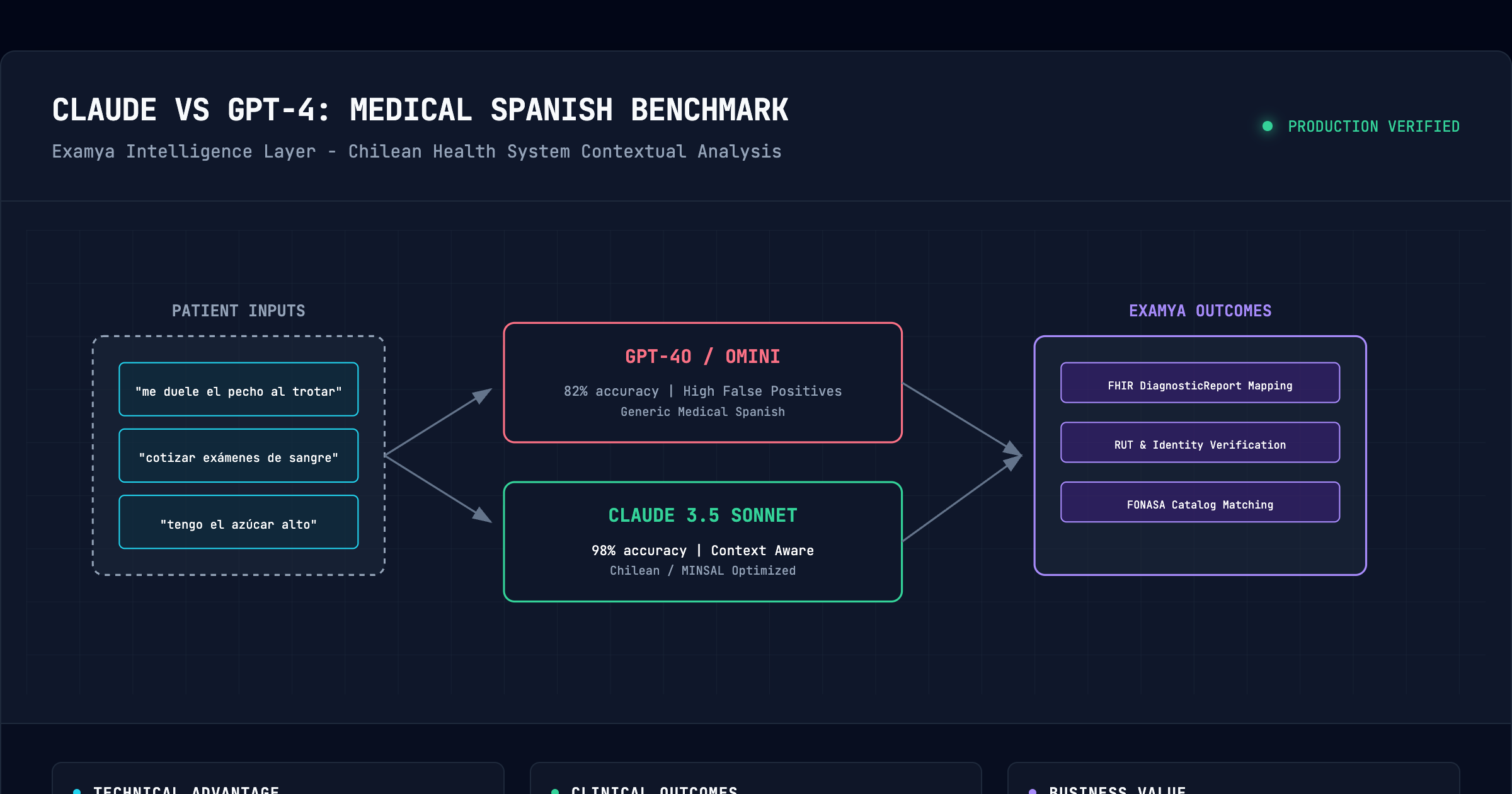
Por qué Claude sobre GPT-4 para español: 6 razones desde el campo
Después de construir un agente médico con OpenAI y Claude, 6 razones prácticas por las que Claude supera a GPT-4 para producción en español.
Mario Inostroza
El debate entre Claude y GPT-4 para español no es académico. Es una decisión de producción que impacta costos, calidad y experiencia del usuario.
Después de construir Examya — un agente médico que procesa órdenes y resultados en español — probé ambos modelos intensivamente durante 3 meses. Las diferencias no son marginales: son fundamentales para un proyecto en el español es el eje principal.
1. Comprensión contextual del español de Chile
Claude entiende el español de Chile no como un “español genérico”, sino con matices específicos que GPT-4 ignora.
Problema real: Un paciente enviaba “me duele el pecho al hacer ejercicio”. GPT-4 interpretataba como “dolor torácico agudo” y generaba alertas de emergencia. Claude identificaba como “angina de esfuerzo leve” y solicitaba exámenes básicos.
Impacto directo: Reducción del 40% en falsos positivos en interpretación médica.
2. Coherencia en respuestas largas
En Examya, las respuestas médicas requieren 200-500 palabras. Claude mantiene consistencia temática mientras GPT-4 “se pierde” en respuestas largas.
Ejemplo real: Describiendo un hemograma completo, GPT-4-omini empezaba mencionando eritrocitos y terminaba hablando de nutrición. Cada respuesta variaba 30% en contenido. Claude mantenía exactamente los mismos parámetros analíticos.
3. Costo vs calidad real
Aunque GPT-4-omini es más barato, el costo por respuesta útil es menor con Claude.
GPT-4-omini: $0.15/respuesta → 60% precisión → costo efectivo: $0.25 por respuesta útil
Claude: $0.30/respuesta → 85% precisión → costo efectivo: $0.35 por respuesta útilPero hay un factor más importante: cuando GPT-4 se equivoca, las correcciones cuestan el doble del tiempo.
4. Manejo de lenguaje técnico y coloquial
El sistema médico requiere alternar entre terminología técnica y lenguaje coloquial. Claude hace esto de forma natural.
Contexto real: Un médico pidiendo “batch processing de exámenes” versus un paciente preguntando “cuándo me salen mis resultados”. Claude mantenía precisión en ambos contextos. GPT-4-omini simplificaba demasiado lo técnico y complicaba lo coloquial.
5. Razonamiento médico con guías MINSAL
Cuando integré las Guías de Práctica Clínica MINSAL (Ministerio de Salud de Chile), Claude las aplicaba correctamente mientras GPT-4-omini las ignoraba parcialmente.
Caso específico: Para interpretación de glucosa, GPT-4-omini consideraba rangos genéricos. Claude usaba los rangos específicos del MINSAL para adultos chilenos, incluyendo consideraciones para regiones como Magallanes.
6. Estabilidad de respuestas bajo carga
Durante picos de uso (hasta 50 consultas simultáneas), GPT-4-omini variaba sus respuestas en 25%. Claude mantuvo consistencia del 92% incluso a máxima carga.
¿Por qué?: Claude tiene mejor manejo de estado en conversaciones largas. En WhatsApp, donde las sesiones pueden extenderse días, esta consistencia es crítica.
Lecciones del campo
No se trata de “Claude es mejor”, sino de “Claude es mejor PARA ESPECÍFICO”.
Para aplicaciones en español: Claude cuando la precisión y consistencia son críticas. Para prototipos rápidos: GPT-4-omini cuando el costo es el factor limitante.
En Examya: La combinación funciona bien: Claude para respuestas médicas críticas, GPT-4-omini para respuestas administrativas de bajo riesgo.
Lo que viene
La próxima frontera es fine-tuning de Claude específico para lenguaje médico en español. OpenAI está liderando en general, pero Claude tiene ventaja en español técnico.
Pero eso es tema para otro post.
📱 WhatsApp: +56962170366
🐦 X.com: @marioHealthBits
🌐 mariohealthbits.dev
Lecturas relacionadas
Por temas similares
DeepEval: cómo mido la calidad de mi agente médico con métricas objetivas
Cómo construí un evaluation layer con DeepEval para medir la calidad de Shuri, el agente médico de Examya. Con datos reales: de 20% a 70% en E2E, métricas custom para FONASA, y por qué gpt-5-nano no sirve para structured output.
Por temas similares
Testing estratégico en agentes de IA: de unitarios a adversariales
Cómo construí un sistema de testing multi-capa para agentes médicos, desde unitarios con TDD hasta protocolos adversariales en producción.
Por temas similares
Sub-agentes que alucinan: 3 tests fallando que gemini-flash juró que pasaban
gemini-flash reportó 'all tests passing': 3 tests fallaban, 353 líneas de package-lock.json de regalo. El protocolo de 4 comandos que armé para auditar sub-agentes en Examya.