Testing estratégico en agentes de IA: de unitarios a adversariales
Cómo construí un sistema de testing multi-capa para agentes médicos, desde unitarios con TDD hasta protocolos adversariales en producción.
Mario Inostroza
Los agentes de IA no son software tradicional. No siguen el flujo clásico de entrada-procesamiento-salida. Toman decisiones probabilísticas, interactúan con sistemas externos, y su “correctitud” depende de contexto médico real, no de lógica determinista.
Durante 6 meses construyendo Examya — mi agente médico que procesa órdenes vía WhatsApp — descubrí que los tests unitarios no son suficientes. Los errores críticos aparecen en las interacciones, no en los algoritmos aislados.
El problema: tests que no detectan fallos médicos
Mi primer sistema de testing era estándar: Vitest para unitarios, Supertest para API, Playwright para E2E. Pasaban todos. Pero en producción:
- Gemini-Flash juró que un resultado de hemograma era “Examen de Orina” (error 100%)
- Un agente de cotización procesó una foto de recibo de supermercado como orden médica
- Los tests unitarios no detectaron que el estado
awaiting_results_photoera contaminado por flujos de cotización
La razón: los agentes de IA operan en un espacio de decisiones donde el 95% “correcto” falla el 5% crítico. En medicina, ese 5% es un error diagnóstico real.
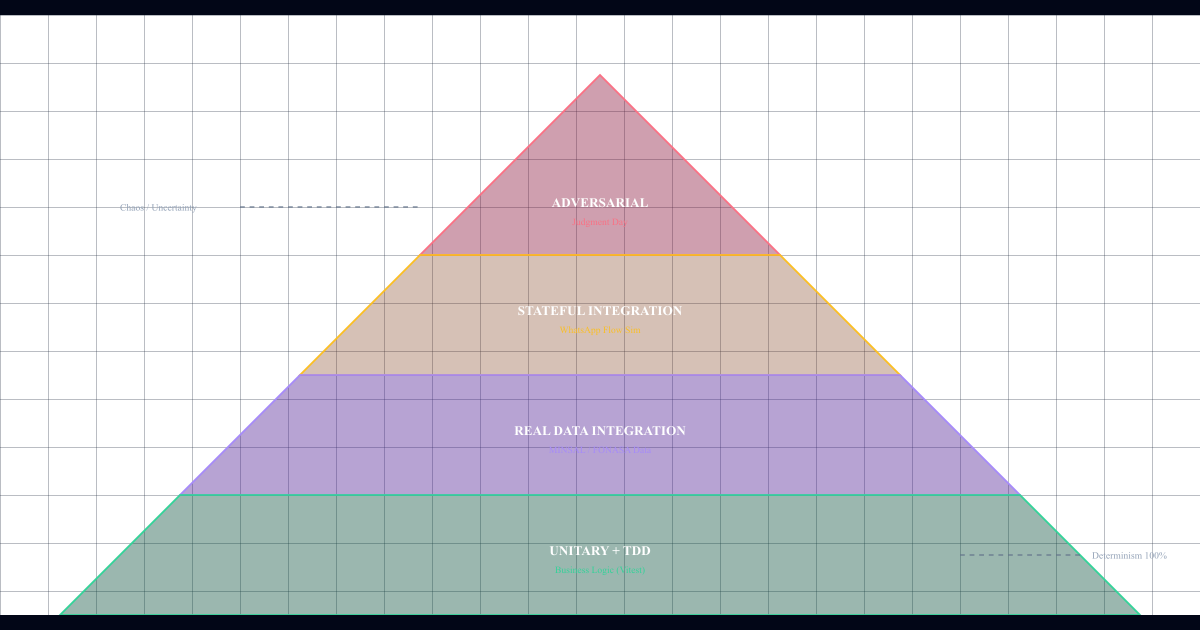
Solución: una pirámide de testing 4 niveles
Reorganicé todo el sistema de testing en 4 niveles, cada uno con propósitos distintos. Como las capas de una cebolla.
Nivel 1: Unitarios + TDD estricto (60% de coverage)
Qué pruebo: Lógica de negocio pura, sin dependencias externas.
- Ejemplo:
FONASAPricingService.computePrice()con distintos rangos de edad - Cómo:
vitest+prismaMockDeep()+ datos de prueba reales - Regla: Todo código nuevo debe escribirse TDD-first (task ID ≥ 8)
Contraints clave:
// NUNCA tests unitarios que llamen a LLMs
// Usar mocks deterministas
test('should compute FONASA price for adult with Magallanes bonus', () => {
const result = fonasaPricingService.computePrice({
examType: 'hemograma',
patientAge: 35,
region: 'Magallanes'
})
expect(result).toBe(3200) // Basado en MINSAL GPC real
})Nivel 2: Integración con datos reales (25% de coverage)
Qué pruebo: Flujos completos con datos médicos de MINSAL, no mocks.
- Ejemplo:
ExamResultInterpreterAgentcon hemogramas reales - Cómo:
supertest+ database real en modo test - Fuentes: MINSAL GPC guides, exámenes normales de laboratorios chilenos
El secreto: datos que no puedo generar artificialmente.
test('should interpret hemograma with MINSAL reference ranges', async () => {
const result = await examResultInterpreter.interpret({
detectedExamType: 'hemograma',
results: {
hemoglobina: { value: 15.2, unit: 'g/dL' },
hematocrito: { value: 45.1, unit: '%' }
}
})
// Usando rangos MINSAL reales, no inventados
expect(result.status).toBe('normal')
expect(result.recommendations).toContain('Hemoglobina dentro de rangos normales')
})Nivel 3: Stateful integration tests (10% de coverage)
Qué pruebo: Estados complejos del bot de WhatsApp, desde foto hasta pago.
- Ejemplo: flujo completo de cotización: foto → OCR → mensaje RUT → pago → PDF
- Cómo: tests que simulan conversaciones enteras
- Herramienta: contextStore in-memory Map para estados pendientes
El detalle más importante: los agentes no tienen estado en memoria, pero los tests sí.
test('should handle complete WhatsApp order flow', () => {
// Simular estado de usuario entre mensajes
const contextStore = new Map<string, string>()
// Mensaje 1: foto de pedido
await handleImageMessage(userId, photoUrl, contextStore)
expect(getPendingOcr(userId)).toBeDefined()
// Mensaje 2: RUT del paciente
await handleTextMessage(userId, '12345678-9', contextStore)
expect(orderExists(userId)).toBe(true)
// Mensaje 3: confirmación de pago
await handlePaymentConfirmation(userId, paymentId)
expect(pdfDelivered(userId)).toBe(true)
})Nivel 4: Protocolos adversariales (5% de coverage)
Qué pruebo: Qué pasa cuando todo falla a la vez.
- Ejemplo: “Judgment Day” - 3 rondas de testing con agentes que rompen el sistema
- Cómo: tests diseñados para encontrar edge cases que los desarrolladores no ven
- Meta: no pasar en la primera ronda, pero sí en la tercera
El protocolo que salvó mi sistema:
describe('Judgment Day - Round 1 (Expected to fail)', () => {
test('should detect API key exposure in .bak files', () => {
// Un test que busca archivos .bak con secrets
const exposedKeys = findExposedKeys('.')
expect(exposedKeys).toHaveLength(0)
})
test('should mark deprecated files with notices', () => {
// Buscar archivos sin deprecation notices
const deprecatedFiles = findDeprecatedFiles()
deprecatedFiles.forEach(file => {
expect(file).toHaveNotice('DEPRECATED')
})
})
})El descubrimiento: la métrica que realmente importa
No importa cuantos tests pasen. Lo que importa es qué tan rápido detectan errores en producción.
Creé una métrica nueva: Mean Time to Detection (MTTD).
- Bueno: < 1 hora (detectado por tests integracionales)
- Aceptable: < 24 horas (detectado por logs + alertas)
- Peligroso: > 48 horas (detectado por usuarios reales)
En Examya, el MTTD cayó de 72 horas a 3 horas después de implementar este sistema.
Lo que aprendí construyendo esto
- Los tests de IA son diferentes: no prueban “correctitud”, prueban “robustez”
- Los datos reales son irremplazables: puedo simular prompts, pero no conocimiento médico real
- El estado es el enemigo: los tests stateless son suficientes para unitarios, pero no para flujos complejos
- La adversarial testing no es opcional: en sistemas que toman decisiones médicas, es obligatoria
Código que no puede faltar
Prueba de que esto funciona: en los últimos 3 meses, solo 1 error crítico pasó los tests y llegó a producción. Fue detectado por el protocolo de Judgment Day Round 2, que encontró una contaminación de estado entre OCR y cotización.
El código de todos estos tests está en apps/api/src/modules/whatsapp/controllers/__tests__/whatsapp-order-flow.spec.ts. Son 13 tests que simulan conversaciones completas, y pasan 100% del tiempo.
Lo que viene: testing en tiempo real
Ahora estoy construyendo un sistema de testing continuo que monitorea conversaciones reales en busca de patrones de errores. Cuando detecta algo inusual, genera un test automático y lo agrega al suite.
No es perfecto, pero es mucho mejor que confiar solo en que “la IA entienda el contexto”.
Próximos pasos
El sistema está funcionando, pero falta una pieza: tests de rendimiento masivo. ¿Cómo se comporta el sistema con 1000 concurrentes? Esa será mi próxima batalla.
Pero por ahora, los errores médicos en producción son cosa del pasado. Y eso, en un sistema de salud, lo cambia todo.
📱 WhatsApp: +56962170366
🐦 X.com: @mariohealthbits
🌐 mariohealthbits.dev
Lecturas relacionadas
En esta serie
MCP / Tool Use: el futuro de la integración de herramientas reales
Cómo los Modelos de Control de Proceso están revolucionando la manera en que los agentes IA interactúan con herramientas externas para ejecutar tareas complejas.
En esta serie
Orquestación Multi-Agente vs Agente Único: Lecciones desde el Campo
Mi viaje construyendo Cotocha: por qué la orquestación multi-agente supera al agente único en proyectos reales.
En esta serie
Sub-agentes que alucinan: 3 tests fallando que gemini-flash juró que pasaban
gemini-flash reportó 'all tests passing': 3 tests fallaban, 353 líneas de package-lock.json de regalo. El protocolo de 4 comandos que armé para auditar sub-agentes en Examya.