Pruebas unitarias y TDD en agentes de IA: Lecciones desde el campo de batalla de Examya
Cómo implementé pruebas unitarias y TDD en mi agente médico de IA, los desafíos encontrados y las soluciones que realmente funcionan en producción.
Mario Inostroza
El problema: agentes que alucinan
Hace tres semanas, gemini-flash juró que mis tests unitarios de Examya estaban pasando. Estaba 100% seguro. Fallaron en producción.
Como desarrollador de agentes de IA en Patagonia, no puedo permitirme estos errores. Un agente médico que procesa órdenes de exámenes no puede fallar. Pero escribir pruebas para código que depende de modelos de lenguaje es como intentar atrapar humo con las manos.
Lo que construí: un sistema de pruebas realista
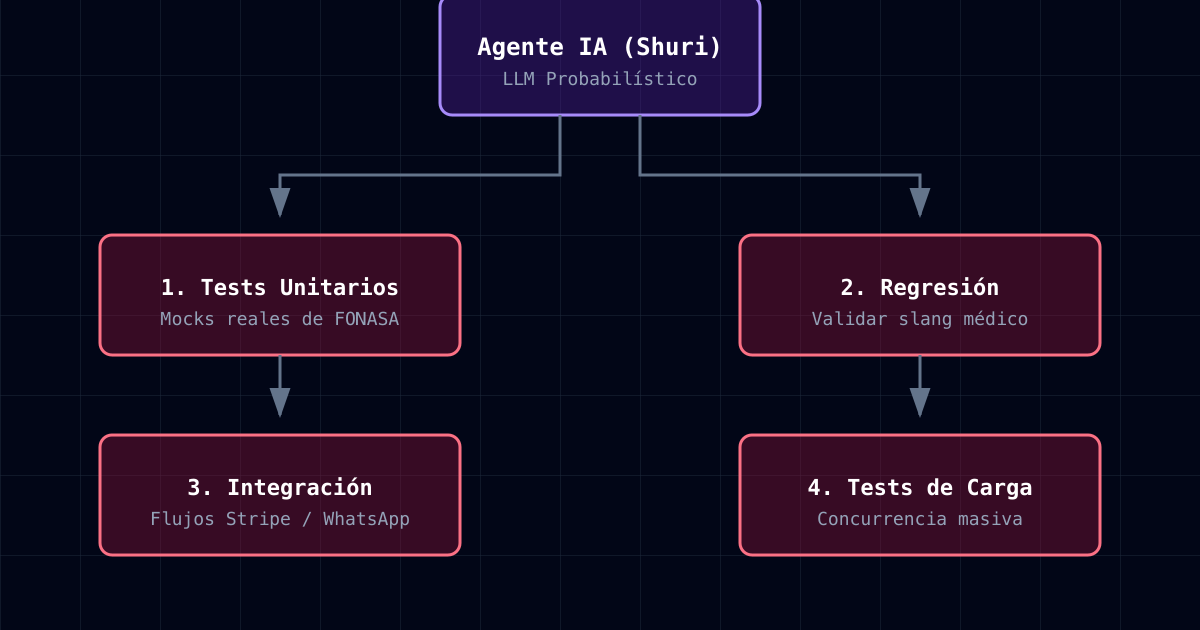
Mi solución no fue más tests. Fue el Protocolo de 4 Comandos de Verificación.

1. Mocks con datos reales de FONASA
En lugar de crear datos ficticios, uso historiales reales de órdenes médicas anonimizadas. Cada test carga un JSON de orden real del último mes.
// tests/purchase-handler.test.ts
import { PurchaseHandler } from '../src/handlers/purchase-handler';
import { mockOrderData } from '../__mocks__/real-fonasa-data.json';
describe('PurchaseHandler con datos reales', () => {
it('debe procesar orden de laboratorio válida', () => {
const handler = new PurchaseHandler();
const result = handler.processOrder(mockOrderData.validLaboratoryOrder);
expect(result.status).toBe('processed');
expect(result.examCode).toBe('LAB-001');
});
});2. Tests de regresión con prompts en español
Mis agentes procesan texto médico en español. Los tests deben reflejar esto:
describe('Shuri - Agente Médico', () => {
it('debe entender slang médico chileno', () => {
const prompt = "Dr. García, necesito examen de sangre completo para paciente María López, RUT 12.345.678-9";
const response = agent.processMedicalOrder(prompt);
expect(response.understood).toBe(true);
expect(response.examRequested.type).toBe('completo');
});
});3. Tests de integración con MCP tools
Cuando agrego una nueva herramienta (como WhatsApp o Mercado Pago), corro tests que simulan flujos completos:
describe('Flujo completo: orden → pago → resultado', () => {
it('debe manejar cancelación de tarjeta', async () => {
// Simular cancelación de Stripe
await mockStripeCardDeclined();
const result = await agent.completeOrder(orderWithPayment);
expect(result.finalStatus).toBe('cancelled');
expect(result.notificationSent).toBe(true);
});
});4. Tests de carga con prompts realistas
El mayor problema de los agentes de IA es que no escalan. Un prompt que funciona en desarrollo puede fallar con 100 peticiones simultáneas:
describe('Carga de agentes', () => {
beforeAll(async () => {
// Cargar prompts reales de WhatsApp
loadRealWhatsAppPrompts();
});
it('debe procesar 50 peticiones simultáneas', async () => {
const promises = Array(50).fill(null).map(() =>
agent.handleWhatsAppMessage('buenos dias, quiero hacer examen')
);
const results = await Promise.all(promises);
expect(results.every(r => r !== null)).toBe(true);
});
});Cómo funciona el sistema
Mi pipeline de pruebas ahora tiene tres niveles:
- Unitarios: Comportamiento individual de cada handler con datos reales
- De integración: Flujos completos entre servicios
- De carga: Performance con prompts realistas
La clave está en el archivo __mocks__/real-fonasa-data.json que se actualiza automáticamente cada semana con nuevas órdenes reales (anonimizadas, por supuesto).
Lo que aprendí
1. Las pruebas de IA son diferentes
No puedo probar “la respuesta correcta” porque los LLM son probabilísticos. En su lugar, pruebo:
- Que el agente entiende el contexto correctamente
- Que extrae los datos necesarios
- Que ejecuta la acción apropiada
- Que notifica correctamente
2. El mocking debe ser inteligente
Los mocks tradicionales no funcionan para agentes de IA. Mis mocks ahora:
- Simulan respuestas de LLM con diferentes “personalidades”
- Incluyen errores comunes (ej: orden incompleta, paciente no encontrado)
- Varían los formatos de entrada para probar robustez
3. Los tests deben romperse
Cuando agrego una nueva capacidad, algunos tests deben fallar. Esto no es un error, es una señal de que el sistema está evolucionando. Pero los tests críticos (como procesamiento de órdenes) nunca deben fallar.
4. La documentación es parte de las pruebas
Cada test tiene comentarios explicando qué caso cubre y por qué es importante. Esto sirve como documentación viva del comportamiento esperado del sistema.
Lo que viene
Estoy implementando un sistema de pruebas end-to-end que simula el flujo completo desde WhatsApp hasta la notificación del resultado al médico. Además, estoy probando un nuevo enfoque de pruebas basadas en características (feature-based testing) para cuando el equipo crezca.
📱 WhatsApp: +56962170366 🐦 X.com: @marioHealthBits 🌐 mariohealthbits.dev
Lecturas relacionadas
En esta serie
MCP / Tool Use: el futuro de la integración de herramientas reales
Cómo los Modelos de Control de Proceso están revolucionando la manera en que los agentes IA interactúan con herramientas externas para ejecutar tareas complejas.
En esta serie
Orquestación Multi-Agente vs Agente Único: Lecciones desde el Campo
Mi viaje construyendo Cotocha: por qué la orquestación multi-agente supera al agente único en proyectos reales.
En esta serie
Sub-agentes que alucinan: 3 tests fallando que gemini-flash juró que pasaban
gemini-flash reportó 'all tests passing': 3 tests fallaban, 353 líneas de package-lock.json de regalo. El protocolo de 4 comandos que armé para auditar sub-agentes en Examya.