Por qué los subagentes sirven más como revisores que como escritores
Lanzar 5 agentes a escribir código en paralelo es un desastre. Por qué invertimos el patrón: 1 escritor y 5 revisores adversarios ciegos.
Mario Inostroza
Cuando empiezas a orquestar agentes IA, la primera tentación siempre es la misma: la ejecución en paralelo. “Voy a lanzar 5 subagentes para que escriban 5 componentes distintos al mismo tiempo”. Suena increíble en la cabeza.
En la práctica, lo matai. Terminas con conflictos de merge infernales, estado roto y agentes pisándose la cola porque carecen de la sincronización implícita que tiene un equipo humano. Escribir código de forma concurrente escala la complejidad, no la productividad.
Lo que nadie te cuenta del paralelismo
Si pones a múltiples LLMs a generar código sobre el mismo repositorio sin un control de concurrencia estricto, compiten por los mismos recursos. Asumen que el estado del sistema es el que leyeron hace 10 segundos, ignorando lo que el agente de al lado acaba de modificar.
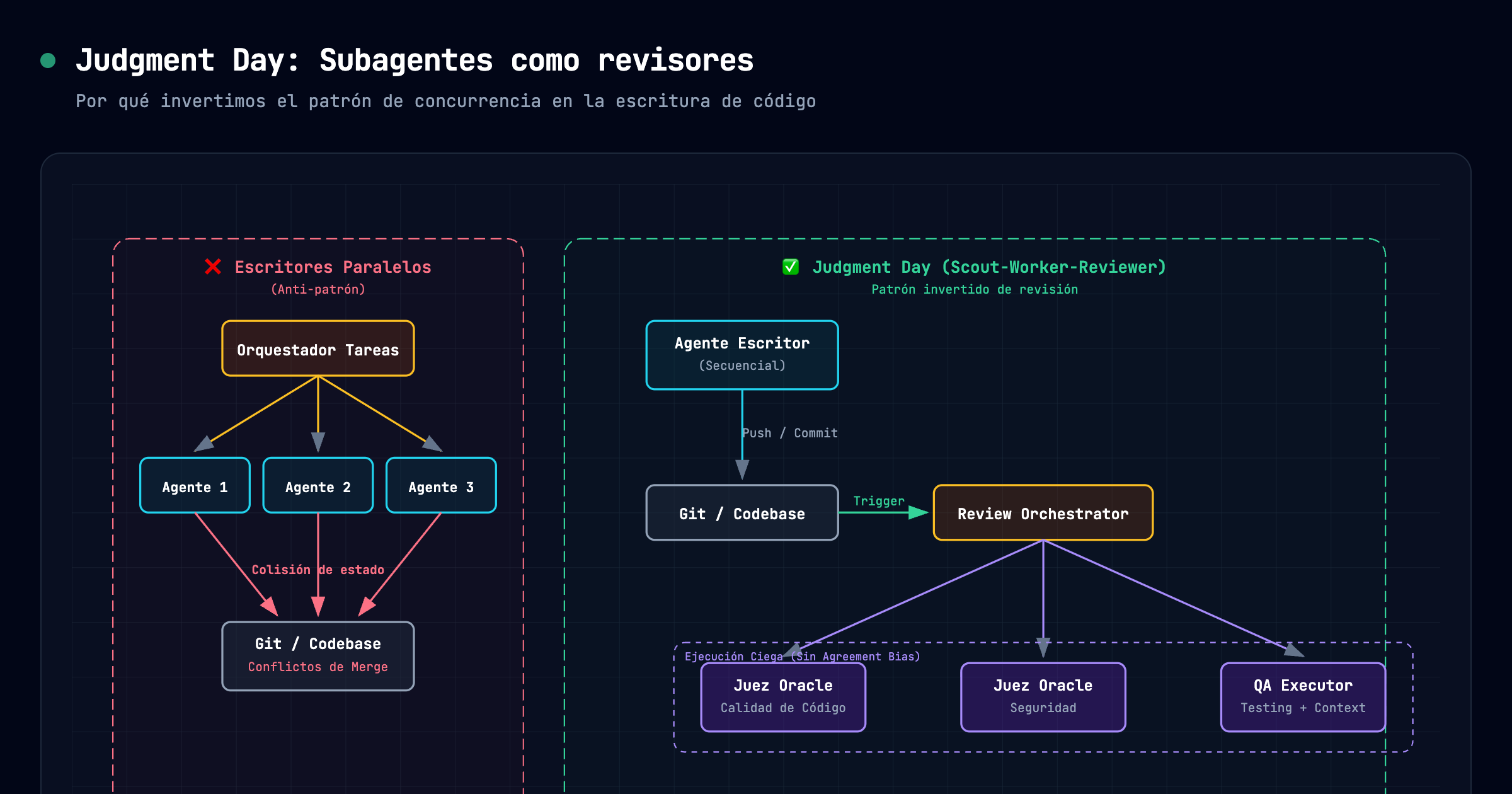
En OpenCode intentamos el esquema de escritores paralelos. Falló miserablemente. La tasa de regresiones se disparó y perdíamos más tiempo arreglando conflictos que si lo hubiéramos escrito a mano. Así que hicimos lo que hace cualquier equipo de ingeniería maduro: invertimos el patrón.
Los datos reales: el orquestador de revisión
En lugar de paralelizar la escritura, paralelizábamos la validación. Nos apoyamos en la skill review-work, un orquestador que viene por defecto en el stack de OpenCode (creado por Alan Buscaglia), que se lanza después de que se escribe el código.
Tiene 1 solo agente escritor, pero lanza 5 subagentes de revisión en estricto background:
- Oracle para verificar calidad de código.
- Oracle para auditar seguridad.
- Un ejecutor QA que corre tests.
- Un minero de contexto que revisa el historial de Git y Engram.
- Un validador de constraints.
Todos tienen que pasar en verde para que el review sea aprobado. Es exactamente como un pipeline de CI/CD, pero semántico y adversarial.
Judgment Day: el protocolo adversarial
Para decisiones críticas o refactors grandes, implementamos el protocolo judgment-day. Este es un esquema de revisión adversarial puro diseñado originalmente por Alan Buscaglia en su stack de agentes, al cual le hemos hecho ajustes y tuneos finos para nuestro flujo clínico. Lanzamos dos subagentes “jueces” de forma simultánea e independiente para auditar el mismo objetivo.
# Extracto del protocolo Judgment Day
protocol: adversarial-review
judges: 2
mode: blind-parallel
escalation_max_iterations: 2Ambos evalúan, sintetizan hallazgos y aplican correcciones. Si hay discrepancias, iteran. Si no se ponen de acuerdo después de dos rondas, escalan al humano.
El gotcha: el sesgo de acuerdo
Aquí está el aprendizaje que nos costó semanas entender: si usas subagentes para revisar, deben ser ciegos entre sí en la primera fase.
Si les compartes el contexto de lo que opinó el otro agente demasiado pronto, sufren de “agreement bias”. El LLM tiende a asentir y estar de acuerdo con el análisis previo en lugar de buscar fallas de forma independiente. Para que el judgment-day funcione, la evaluación inicial debe ser estrictamente aislada.
Zoom out
Esto tiene todo el sentido del mundo. No pones a 5 desarrolladores senior a escribir la misma función al mismo tiempo. Tienes un autor, y múltiples checks automatizados y revisiones de pares.
Tratar a los agentes como desarrolladores mágicos independientes es un error de arquitectura. Hay que tratarlos como procesos en un pipeline: la escritura es secuencial; la validación y el QA son masivamente paralelos.
Lo que viene
Estamos expandiendo este patrón scout-worker-reviewer para integrarlo directamente en los pull requests de Examya. La idea no es que la IA haga los PRs sola, sino que cuando un humano o agente envíe código, un enjambre adversarial lo audite antes de que yo siquiera lo mire.
📱 WhatsApp: +56962170366 🐦 X.com: @mariohealthbits 🌐 mariohealthbits.dev
Lecturas relacionadas
Recomendado
Orquestación Multi-Agente vs Agente Único: Lecciones desde el Campo
Mi viaje construyendo Cotocha: por qué la orquestación multi-agente supera al agente único en proyectos reales.
Recomendado
Sub-agentes que alucinan: 3 tests fallando que gemini-flash juró que pasaban
gemini-flash reportó 'all tests passing': 3 tests fallaban, 353 líneas de package-lock.json de regalo. El protocolo de 4 comandos que armé para auditar sub-agentes en Examya.
En esta serie
MCP / Tool Use: el futuro de la integración de herramientas reales
Cómo los Modelos de Control de Proceso están revolucionando la manera en que los agentes IA interactúan con herramientas externas para ejecutar tareas complejas.