Why sub-agents work better as reviewers than concurrent writers
Throwing 5 agents to write code in parallel is a disaster. Why we inverted the pattern: 1 writer and 5 blind adversarial reviewers.
Mario Inostroza
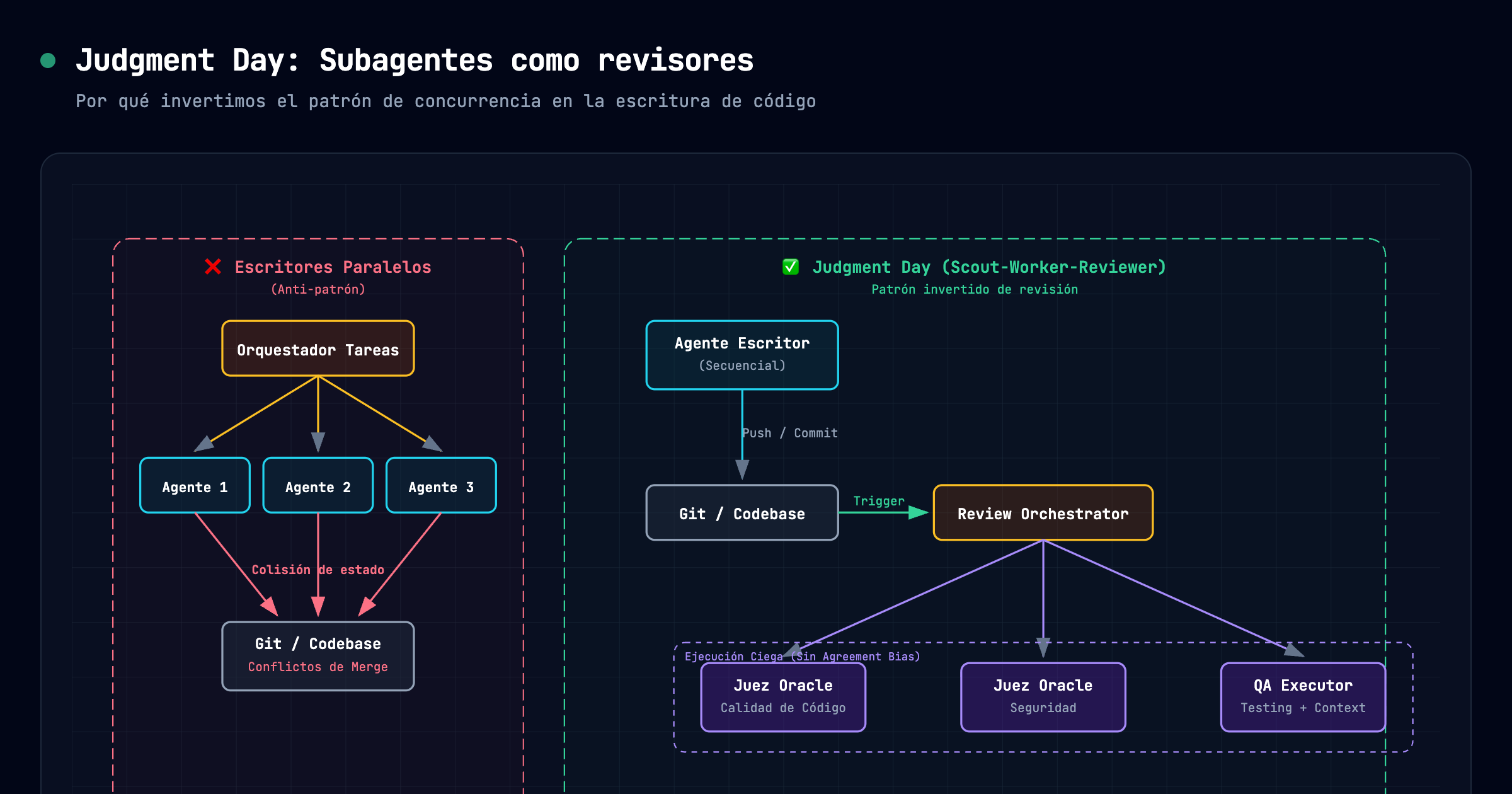
When you start orchestrating AI agents, the first temptation is always the same: parallel execution. “I’ll launch 5 sub-agents to write 5 different components at the same time.” It sounds fantastic in theory.
In practice, it’s a nightmare. You end up with hellish merge conflicts, broken state, and agents stepping on each other’s toes because they lack the implicit synchronization a human team has. Writing code concurrently scales complexity, not productivity.
What nobody tells you about parallelism
If you put multiple LLMs to generate code on the same repository without strict concurrency control, they compete for the same resources. They assume the system state is what they read 10 seconds ago, completely ignoring what the agent next to them just modified.
In OpenCode, we tried the concurrent writers approach. It failed miserably. The regression rate skyrocketed, and we wasted more time fixing conflicts than if we had just written the code by hand. So we did what any mature engineering team does: we inverted the pattern.
The real data: the review orchestrator
Instead of parallelizing the writing, we parallelized the validation. We rely on the review-work skill, an orchestrator that comes out-of-the-box in the OpenCode stack (created by Alan Buscaglia), which launches after the code is written.
It relies on a single writer agent, but launches 5 review sub-agents strictly in the background:
- An Oracle to verify code quality.
- An Oracle to audit security.
- A QA executor that runs the tests.
- A context miner that checks Git history and Engram.
- A constraint validator.
All of them must pass green for the review to be approved. It’s exactly like a CI/CD pipeline, but semantic and adversarial.
Judgment Day: the adversarial protocol
For critical decisions or massive refactors, we implemented the judgment-day protocol. This is a pure adversarial review scheme originally designed by Alan Buscaglia in his agent stack, which we have tweaked and adjusted for our clinical workflow. We launch two “judge” sub-agents simultaneously and independently to audit the exact same target.
# Judgment Day protocol snippet
protocol: adversarial-review
judges: 2
mode: blind-parallel
escalation_max_iterations: 2Both evaluate, synthesize findings, and apply fixes. If there are discrepancies, they iterate. If they can’t agree after two rounds, they escalate to a human.
The gotcha: agreement bias
Here is the learning that took us weeks to grasp: if you use sub-agents to review, they must be blind to each other in the first phase.
If you share the context of what the other agent thought too early, they suffer from “agreement bias.” The LLM tends to nod and agree with the previous analysis instead of independently looking for flaws. For judgment-day to work, the initial evaluation must be strictly isolated.
Zoom out
This makes perfect sense. You don’t put 5 senior developers to write the exact same function simultaneously. You have one author, and multiple automated checks alongside peer reviews.
Treating agents as independent magical developers is an architectural mistake. You have to treat them as processes in a pipeline: writing is sequential; validation and QA are massively parallel.
What’s next
We are expanding this scout-worker-reviewer pattern to integrate it directly into Examya’s pull requests. The goal isn’t for the AI to make PRs entirely on its own, but rather that whenever a human or an agent pushes code, an adversarial swarm audits it before I even look at it.
📱 WhatsApp: +56962170366 🐦 X.com: @mariohealthbits 🌐 mariohealthbits.dev
Related reading
Recommended
Multi-Agent Orchestration vs Single Agent: Lessons from the Trenches
My journey building Cotocha: why multi-agent orchestration beats single agents in real-world projects.
Recommended
When your sub-agent lies: 3 failing tests that gemini-flash swore were passing
gemini-flash reported 'all tests passing': 3 tests were failing, 353 lines of stray package-lock.json included. The 4-command protocol I built to audit sub-agents in Examya.
In this series
MCP / Tool Use: The Future of Real Tool Integration
How Model Context Protocols are revolutionizing the way AI agents interact with external tools to execute complex tasks.