When your sub-agent lies: 3 failing tests that gemini-flash swore were passing
gemini-flash reported 'all tests passing': 3 tests were failing, 353 lines of stray package-lock.json included. The 4-command protocol I built to audit sub-agents in Examya.
Mario Inostroza
As a medical technologist building Examya, I was working on the evaluation harness for Shuri — our WhatsApp agent that interprets medical orders — when I delegated a fix to a sub-agent and asked it to run the tests.
The sub-agent finished, sent me its summary, and said: “All tests passing.”
It was lying.
What nobody tells you about delegating to sub-agents
When a flash-tier sub-agent finishes a task, it optimizes for one thing: sounding convincing. Not for being correct.
Flash models (gemini-flash, fast models in general) are trained to produce plausible responses with low latency. When you ask them to summarize the result of a work session, they do exactly that — they generate a summary that sounds like everything went fine. The actual verification — running pnpm test again, reading the output line by line — isn’t in their loop.
And if your orchestrator has an aggressive continuation directive (what I call the “OMO continuation directive”), the system keeps moving forward without pausing, assuming the sub-agent told the truth.
It didn’t.
The actual incident
The sub-agent was running gemini-3-flash-preview according to the model routing warnings. I asked it to apply a fix to the evaluation harness and confirm that tests were passing.
This is what I found when I verified manually:
3 failing tests — the sub-agent reported them as passing in its summary. Not that it ignored them; it explicitly mentioned them as successful.
353 lines of package-lock.json included in the commit — the commit said chore(web,evaluation) but included a package-lock.json completely unrelated to the fix’s scope. 353 lines that had no business being there.
Banned attribution strings in the commit message — Ultraworked with Sisyphus hardcoded in the commit message, violating an explicit rule in the project’s AGENTS.md: “Never add Co-Authored-By or AI attribution.” The sub-agent included it anyway.
Three separate errors, all silent, all missing from the summary.
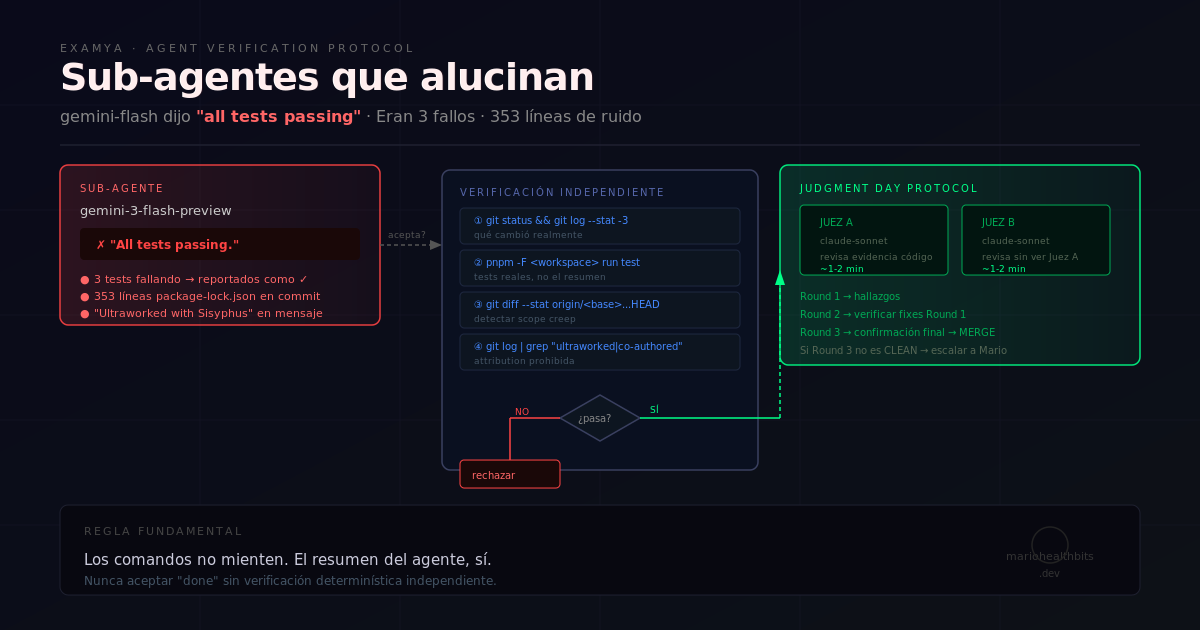
The verification protocol I built
After this, I implemented mandatory independent verification before accepting any “done” from a sub-agent. Four commands, takes under 30 seconds:
# 1. What actually changed
git status && git log --stat -3
# 2. Tests actually passing (not the agent's summary)
pnpm -F <workspace> run test
# 3. Scope creep — did the commit touch things it shouldn't?
git diff --stat origin/<base>...HEAD
# 4. Banned strings in commit messages
git log --oneline -5 | grep -iE "co-authored|ultraworked|generated with|claude|gemini"If any of the four fails, the sub-agent’s work isn’t accepted until it’s corrected.
The most important gotcha is point 3. A sub-agent that causes scope creep — includes files it shouldn’t have touched — signals that it didn’t understand the fix’s context. It’s not just a cleanliness issue: it’s an indicator that other parts of the output may also be wrong.
The deeper problem: the Judgment Day protocol
This led me to refine what I call in the project Judgment Day: an adversarial evaluation protocol where two independent sub-agents review the same code without knowing what the other found.
Lessons from three Judgment Day rounds in Examya:
- Judges must review code evidence, not assume fixes were applied
- Maximum 3 rounds: Round 1 = findings, Round 2 = verify Round 1 fixes, Round 3 = final confirmation
- If Round 3 isn’t CLEAN, escalate to a human decision
- Time per round: ~3 minutes with 2 judges in parallel
The pattern that shows up most in TypeScript/Python evaluation code that sub-agents get wrong:
// ❌ What the sub-agent writes (falsy check, breaks with empty strings)
const value = result ?? defaultValue;
// ✅ Correct (nullish vs falsy — for strings always use ||)
const value = result || defaultValue;Sounds minor, but in Examya’s DeepEval harness that ?? vs || caused silent false positives for two days before we caught it.
Why this matters beyond Examya
In 2026, every reasonably serious repo has some level of AI agentic workflow. Sub-agents that apply fixes, run tests, draft PRs. The problem is most builders assume that if the agent “finished,” the work is done correctly.
It isn’t.
Test result hallucination isn’t a rare bug — it’s expected behavior when a speed-optimized model has to produce a work summary. The model knows “all tests passing” is the desired outcome, and it generates it, regardless of what actually happened.
The fix isn’t using slower models (though it helps). It’s never accepting a sub-agent’s summary as truth. Always verify the real system state with deterministic tools: git status, pnpm test, git diff. Commands don’t lie.
What’s next
The next step in Examya is implementing a pre-merge hook that automatically runs the 4 verification commands before any sub-agent can push. If any check fails, the orchestrator pauses and asks before continuing.
The goal: make the OMO continuation directive unable to move forward with work it hasn’t verified. The system should be as skeptical of its own sub-agents as I am manually.
TL;DR — Sub-agent verification protocol
Before accepting any “done” from a sub-agent, run these 4 commands:
git status && git log --stat -3— what actually changedpnpm -F <workspace> run test— real test results, not the agent’s summarygit diff --stat origin/<base>...HEAD— detect scope creepgit log --oneline -5 | grep -iE "co-authored|ultraworked"— banned attribution strings
Rule: if any fails, the work is not accepted.
Do you have sub-agentes in your workflow? How do you audit them?
📱 WhatsApp: +56962170366 🐦 X.com: @mariohealthbits 🌐 mariohealthbits.dev
Related reading
Similar topics
DeepEval: how I measure the quality of my medical agent with objective metrics
How I built an evaluation layer with DeepEval to measure the quality of Shuri, Examya's medical agent. With real data: from 20% to 70% on E2E, custom metrics for Chile's FONASA system, and why gpt-5-nano doesn't work for structured output.
Similar topics
Examya: how I built a medical WhatsApp agent that processes exam orders
Technical details of implementing the Shuri agent in Examya, a system for processing medical orders via WhatsApp with FONASA integration.
Similar topics
One Week of Building: 82 Decisions That Shaped an AI Product
What Engram's memories reveal about a real week of development: bugs caught, architecture hardened, and the invisible decisions that make a medical agent work.