DeepEval: how I measure the quality of my medical agent with objective metrics
How I built an evaluation layer with DeepEval to measure the quality of Shuri, Examya's medical agent. With real data: from 20% to 70% on E2E, custom metrics for Chile's FONASA system, and why gpt-5-nano doesn't work for structured output.
Mario Inostroza
When your AI agent processes medical orders over WhatsApp, “works fine” is not a metric. You need numbers. You need to know what breaks, where, and why.
Examya has an agent called Shuri that handles the entire flow: the patient describes symptoms, the system suggests exams, validates their national ID (RUT) against Chile’s public health system (FONASA), quotes prices, and generates the order. If Shuri misclassifies an intent or returns the wrong FONASA code, the patient gets incorrect medical information.
So I built an evaluation layer with DeepEval. These are the real metrics, the real failures, and what I learned.
The problem: you don’t know how good your agent is
Before the evaluation layer, validation was manual. I would send test messages through WhatsApp and check the responses. That works for demos. It doesn’t work when you have a production system with real patients.
What I needed was to answer three concrete questions: whether Shuri correctly understands what the patient is asking, whether the FONASA codes it returns are accurate, and whether the complete end-to-end flows work without breaking.
The evaluation layer architecture
The system has 5 phases, built incrementally over one week.
Phase 1 was the foundation. I installed DeepEval, configured the runner, and created the base structure under evaluation/. Phase 2 covered datasets. I generated .jsonl files with real test cases: 15 for intent routing, 10 for exam normalization, 20+ for E2E WhatsApp flows. Phase 3 was custom metrics, 7 metrics specific to the Chilean medical domain: patient_safety.py, chile_rut.py, fonasa_match.py, chile_reference_range.py, spanish_chile.py, urgency_recall.py, and medical_accuracy.py. Phase 4 covers critical suites: OCR, result interpretation, urgency detection, RAG against MINSAL regulations, medical routing. And Phase 5 covers integration suites: intent router, conversational, exam normalization, document classification, clinical AI, E2E WhatsApp.
evaluation/
├── clients/ # HTTP clients per service
│ └── base.py # BaseClient with 120s timeout
├── datasets/ # .jsonl test cases
├── metrics/ # 7 custom Chile/medical metrics
├── tests/ # 11 test suites (Phase 4 + 5)
├── reports/ # Results from each run
└── conftest.py # Shared fixturesThe real numbers
The first baseline revealed the truth.
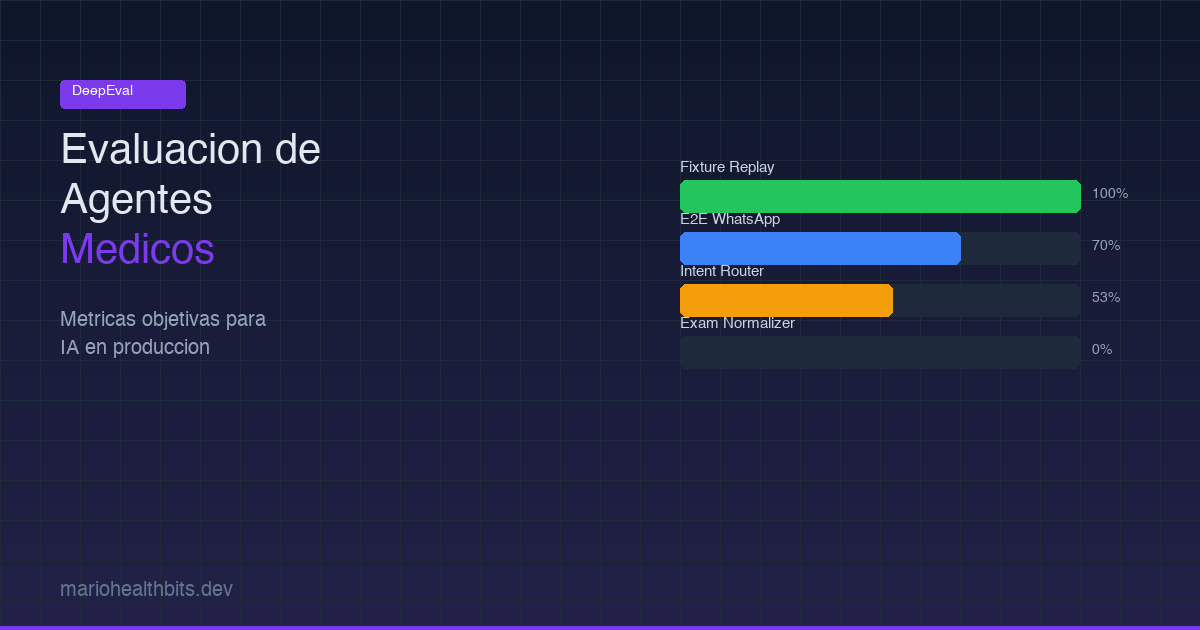
Fixture-replay suites (urgency, classifier, clinical) scored 165/165, a perfect 100%. These are the CI gate. No excuse for failing here since they use pre-recorded responses.
E2E WhatsApp started at 20% with degraded mode (regex with fixed 0.6 confidence). After switching to gpt-4.1-mini in full mode, it jumped to 70%. The improvement came from better conversational context understanding, not code changes.
The intent router in full mode reached 53% (8/15 cases). In degraded mode: 20%. The failures are specific: it confuses request_exams with api_error when context is short. It knows something is being requested but can’t distinguish what.
The exam normalizer was the toughest. First run: 0%. GEval average 0.559, FONASA Match Rate 0.225. The problem: it returns “funcion hepatica” when the catalog expects “PERFIL HEPÁTICO”. This isn’t a harness issue, it’s a real agent problem where names aren’t canonicalized.
What gpt-5-nano can’t do
During model optimization I found something that isn’t in the official documentation.
OpenAI’s reasoning models (gpt-5-nano, gpt-5-mini) have two hard constraints. First, temperature only accepts value 1. If you send 0.3, it returns HTTP 400. Second, max_tokens doesn’t exist, you need max_completion_tokens.
But the worst part: gpt-5-nano returns empty JSON in json_object mode. Literally {}. It doesn’t work for structured output. This broke the ExamResultInterpreterAgent which needs to parse exam results into structured formats.
The solution was creating a per-agent fallback system. The default model is gpt-4.1-mini for most agents, gpt-4.1 for the interpreter (needs precision), and gpt-4o-mini for OCR. Not one model for everything.
// models.ts — each agent gets its optimal model
export function getModelForAgent(agent: string): string {
switch (agent) {
case "interpreter": return "gpt-4.1";
case "ocr": return "gpt-4o-mini";
default: return "gpt-4.1-mini";
}
}The result: dev costs dropped from ~$10/day to ~$1-2/day.
DeepEval gotchas nobody tells you about
If you’re going to use DeepEval, write these down.
FaithfulnessMetric requires retrieval_context= in LLMTestCase. Not context=. They’re different fields and the error isn’t clear.
For multi-turn tests you need ConversationalTestCase with turns=[Turn(role=..., content=...)]. If you use a regular LLMTestCase, it won’t capture conversational context.
TaskCompletionMetric requires @observe tracing. It doesn’t work black-box against external services. The alternative: use GEval with a custom criteria describing the expected task.
For custom metrics, you inherit from BaseMetric and implement measure(), a_measure(), is_successful(), and __name__. The pattern is simple but the documentation doesn’t show it clearly.
And the judge model matters. We use gpt-4.1 as judge. Never use gpt-5-nano as judge, it returns empty JSON.
Custom metrics for Chilean healthcare
The 7 metrics I created are domain-specific.
fonasa_match.py validates that codes returned by the normalizer match the actual FONASA catalog. It’s not enough for the name to sound similar. If the code doesn’t match, the patient gets an incorrect price.
chile_rut.py validates the format and check digit of Chile’s national ID (RUT). Shuri needs to validate RUTs before querying the FONASA API. An invalid RUT means a failed query and a frustrated patient.
urgency_recall.py measures whether the system correctly detects medical emergency situations. This has a threshold of 1.0. No margin for error. If a patient describes heart attack symptoms and the system classifies it as a general consultation, the risk is real.
patient_safety.py is the meta-check. It verifies that no agent response contains dangerous or contradictory medical information. Threshold 1.0 as well.
The evaluation flow
Every evaluation follows the same pattern.
from deepeval import evaluate
from deepeval.test_case import LLMTestCase
from deepeval.metrics import GEval
# 1. Prepare test case
test_case = LLMTestCase(
input="I need a blood test",
actual_output=agent_response,
expected_output="Blood test order with FONASA code 0301045"
)
# 2. Define metric
fonasa_metric = GEval(
name="FONASA Code Match",
criteria="The response must contain the correct FONASA code",
threshold=0.80
)
# 3. Evaluate
results = evaluate(
test_cases=[test_case],
metrics=[fonasa_metric]
)Thresholds are calibrated for Examya: critical >= 0.80, safety = 1.0, WhatsApp E2E >= 0.65 (lower because it includes formatting, emojis, and natural chat variations).
What’s next
The intent router needs staging with a valid service-token to run in full mode. The exam normalizer needs real canonicalization against the FONASA catalog. And I want to integrate evaluations as a CI gate: if fixture-replay suites drop below 100%, the deploy gets blocked.
Evaluation isn’t a nice-to-have. When your agent makes medical decisions, it’s the difference between a reliable product and a liability.
If you’re building AI agents and need to measure quality objectively, this stack works. Find me on X (@marioHealthBits) or WhatsApp.
Related reading
In this series
How I Built Patagonia's First Private COVID PCR Lab (And Why I Ended Up Building AI)
In March 2021, I hoisted 300 kg of biosafety cabinet by crane to a second floor during lockdown. By May we were running the first private COVID PCR tests in Chilean Patagonia. The nights that followed became the real origin of Examya.
In this series
Examya: how I built a medical WhatsApp agent that processes exam orders
Technical details of implementing the Shuri agent in Examya, a system for processing medical orders via WhatsApp with FONASA integration.
In this series
pgvector + Embeddings in Production: The Foundation of Medical Reasoning in Examya
Architecture for semantic search and text similarity in production with pgvector, pg_trgm, and real MINSAL data.