DeepEval: cómo mido la calidad de mi agente médico con métricas objetivas
Cómo construí un evaluation layer con DeepEval para medir la calidad de Shuri, el agente médico de Examya. Con datos reales: de 20% a 70% en E2E, métricas custom para FONASA, y por qué gpt-5-nano no sirve para structured output.
Mario Inostroza
Cuando tu agente de IA procesa órdenes médicas por WhatsApp, “funciona bien” no es una métrica. Necesitás números. Necesitás saber qué se rompe, dónde, y por qué.
Examya tiene un agente llamado Shuri que maneja todo el flujo: el paciente describe síntomas, el sistema sugiere exámenes, valida RUT contra FONASA, cotiza, y genera la orden. Si Shuri clasifica mal un intent o devuelve un código FONASA incorrecto, el paciente recibe información médica equivocada.
Así que construí un evaluation layer con DeepEval. Estas son las métricas reales, los fracasos reales, y lo que aprendí.
El problema: no sabés qué tan bueno es tu agente
Antes del evaluation layer, la validación era manual. Yo mandaba mensajes de prueba por WhatsApp y revisaba las respuestas. Eso funciona para demos. No funciona cuando tenés un sistema en producción con pacientes reales.
Lo que necesitaba era responder tres preguntas concretas: si Shuri entiende correctamente lo que el paciente pide, si los códigos FONASA que devuelve son correctos, y si los flujos completos de principio a fin funcionan sin romperse.
La arquitectura del evaluation layer
El sistema tiene 5 fases, construidas incrementalmente en una semana.
La Fase 1 fue la fundación. Instalé DeepEval, configuré el runner, y creé la estructura base en evaluation/. La Fase 2 cubrió los datasets. Generé archivos .jsonl con casos de prueba reales: 15 para intent routing, 10 para normalización de exámenes, 20+ para flujos WhatsApp E2E. La Fase 3 fueron las métricas custom, 7 métricas específicas para el dominio médico chileno: patient_safety.py, chile_rut.py, fonasa_match.py, chile_reference_range.py, spanish_chile.py, urgency_recall.py, y medical_accuracy.py. La Fase 4 son los suites críticos: OCR, interpretación de resultados, detección de urgencia, RAG contra normativa MINSAL, ruteo médico. Y la Fase 5 son los suites de integración: intent router, conversacional, normalización de exámenes, clasificación de documentos, IA clínica, E2E WhatsApp.
evaluation/
├── clients/ # Clientes HTTP para cada servicio
│ └── base.py # BaseClient con timeout 120s
├── datasets/ # .jsonl con casos de prueba
├── metrics/ # 7 métricas custom Chile/médico
├── tests/ # 11 test suites (Fase 4 + 5)
├── reports/ # Resultados de cada run
└── conftest.py # Fixtures compartidasLos números reales
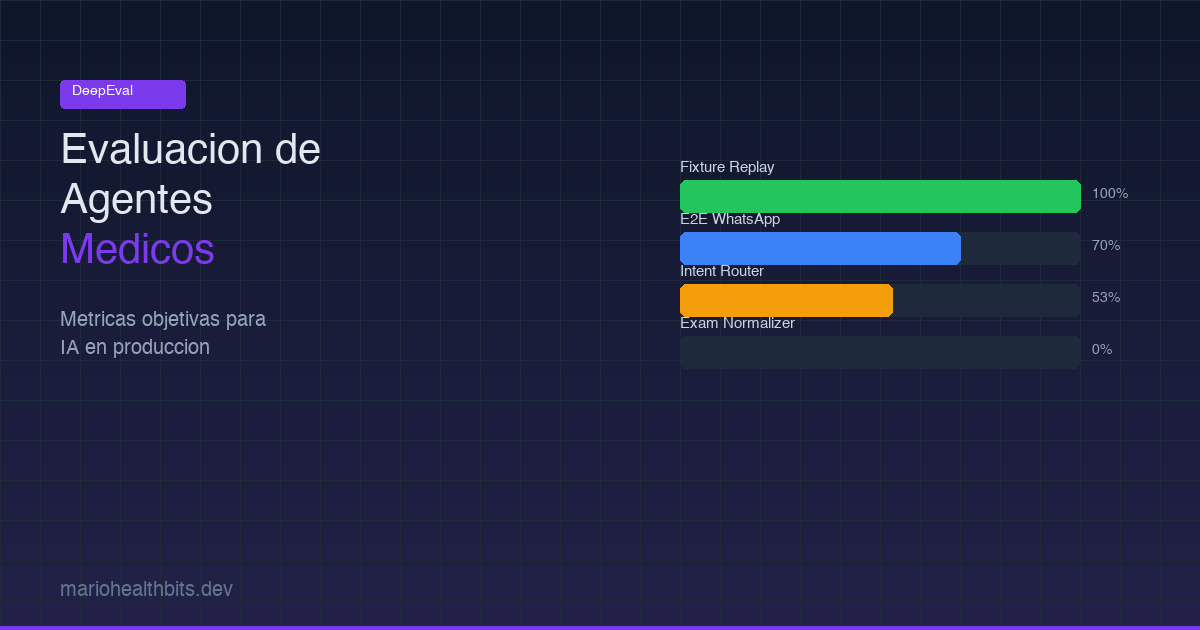
El primer baseline reveló la realidad.
Las fixture-replay suites (urgency, classifier, clinical) dieron 165/165, un 100%. Estas son el gate de CI. No hay excusa para fallar acá porque son respuestas pregrabadas.
El E2E WhatsApp empezó en 20% con el modo degraded (regex con confianza fija 0.6). Después de cambiar a gpt-4.1-mini en full mode, subió a 70%. El salto fue por mejor comprensión de contexto conversacional, no por cambios en el código.
El intent router en full mode llegó a 53% (8/15 casos). En modo degraded: 20%. Los fallos son específicos: confunde request_exams con api_error cuando el contexto es corto. Sabe que algo le están pidiendo pero no distingue qué.
El exam normalizer fue el más duro. Primer run: 0%. GEval promedio 0.559, FONASA Match Rate 0.225. El problema: devuelve “funcion hepatica” cuando el catálogo espera “PERFIL HEPÁTICO”. No es un problema del harness, es un problema real del agente que no canonicaliza nombres.
Lo que gpt-5-nano no puede hacer
Durante la optimización de modelos encontré algo que no está en la documentación oficial.
Los modelos de razonamiento de OpenAI (gpt-5-nano, gpt-5-mini) tienen dos restricciones duras. Primero, temperature solo acepta valor 1. Si mandás 0.3, devuelve HTTP 400. Segundo, max_tokens no existe, hay que usar max_completion_tokens.
Pero lo peor: gpt-5-nano retorna JSON vacío en json_object mode. Literalmente {}. No sirve para structured output. Esto rompió el ExamResultInterpreterAgent que necesita parsear resultados de exámenes en formato estructurado.
La solución fue crear un sistema de fallback por agente. El modelo default es gpt-4.1-mini para la mayoría, gpt-4.1 para el interpreter (necesita precision), y gpt-4o-mini para OCR. No un modelo para todo.
// models.ts — cada agente tiene su modelo óptimo
export function getModelForAgent(agent: string): string {
switch (agent) {
case "interpreter": return "gpt-4.1";
case "ocr": return "gpt-4o-mini";
default: return "gpt-4.1-mini";
}
}El resultado: costos de ~$10/día en dev bajaron a ~$1-2/día.
Las gotchas de DeepEval que nadie te cuenta
Si vas a usar DeepEval, anotate estas.
FaithfulnessMetric requiere retrieval_context= en el LLMTestCase. No context=. Son campos distintos y el error no es claro.
Para tests multi-turn necesitás ConversationalTestCase con turns=[Turn(role=..., content=...)]. Si usás LLMTestCase normal, no captura el contexto conversacional.
TaskCompletionMetric requiere @observe tracing. No funciona black-box contra servicios externos. La alternativa: usar GEval con un criterio custom que describe la tarea esperada.
Para métricas custom, heredás de BaseMetric e implementás measure(), a_measure(), is_successful(), y __name__. El pattern es simple pero la documentación no lo muestra claramente.
Y el judge model importa. Usamos gpt-4.1 como juez. Nunca uses gpt-5-nano como juez, devuelve JSON vacío.
Métricas custom para salud chilena
Las 7 métricas que creé son específicas para el dominio.
fonasa_match.py valida que los códigos devueltos por el normalizer coincidan con el catálogo real de FONASA. No basta con que el nombre suene parecido. Si el código no matchea, el paciente recibe un precio incorrecto.
chile_rut.py valida el formato y dígito verificador del RUT chileno. Shuri necesita validar RUTs antes de consultar la API de FONASA. Un RUT inválido significa una consulta fallida y un paciente frustrado.
urgency_recall.py mide si el sistema detecta correctamente situaciones de urgencia médica. Esto tiene threshold 1.0. No hay margen de error. Si un paciente describe síntomas de infarto y el sistema lo clasifica como consulta general, el riesgo es real.
patient_safety.py es el meta-check. Verifica que ninguna respuesta del agente contenga información médica peligrosa o contradictoria. Threshold 1.0 también.
El flujo de evaluación
Cada evaluación sigue el mismo patrón.
from deepeval import evaluate
from deepeval.test_case import LLMTestCase
from deepeval.metrics import GEval
# 1. Preparar caso de prueba
test_case = LLMTestCase(
input="necesito hacerme un hemograma",
actual_output=agent_response,
expected_output="Orden de hemograma con código FONASA 0301045"
)
# 2. Definir métrica
fonasa_metric = GEval(
name="FONASA Code Match",
criteria="The response must contain the correct FONASA code",
threshold=0.80
)
# 3. Evaluar
results = evaluate(
test_cases=[test_case],
metrics=[fonasa_metric]
)Los thresholds están calibrados para Examya: críticos >= 0.80, safety = 1.0, WhatsApp E2E >= 0.65 (más bajo porque incluye formato, emojis, y variaciones naturales del chat).
Lo que viene
El intent router necesita staging con service-token válido para correr en full mode. El exam normalizer necesita canonicalización real contra el catálogo FONASA. Y quiero integrar las evaluaciones como gate en el CI: si las fixture-replay bajan del 100%, el deploy se bloquea.
La evaluación no es un nice-to-have. Cuando tu agente toma decisiones médicas, es la diferencia entre un producto confiable y un riesgo.
Si estás construyendo agentes de IA y necesitás medir calidad objetivamente, este stack funciona. Me encontrás en X (@marioHealthBits) o por WhatsApp.
Lecturas relacionadas
En esta serie
Cómo instalé el primer lab PCR privado de Magallanes (y por qué terminé construyendo IA)
En marzo 2021, subí un gabinete de 300 kg con grúa al segundo piso en cuarentena patagónica. En mayo procesábamos los primeros PCR COVID privados de Magallanes. Lo que aprendí en esas noches me llevó a construir Examya.
En esta serie
Examya: cómo construí un agente médico para WhatsApp que procesa órdenes de exámenes
Detalles técnicos de la implementación del agente Shuri en Examya, un sistema para procesar órdenes médicas vía WhatsApp con integración FONASA.
En esta serie
pgvector + embeddings en producción: La base de razonamiento médico en Examya
Arquitectura de búsqueda semántica y similitud textual en producción con pgvector, pg_trgm y datos MINSAL reales.