Unit Testing and TDD in AI Agents: Lessons from the Examya Battlefield
How I implemented unit testing and TDD in my medical AI agent, the challenges encountered, and the solutions that actually work in production.
Mario Inostroza
The Problem: Agents That Hallucinate
Three weeks ago, gemini-flash swore my Examya unit tests were passing. It was 100% sure. They failed in production.
As an AI agent developer in Patagonia, I can’t afford these mistakes. A medical agent processing exam orders cannot fail. But writing tests for code that relies on language models is like trying to catch smoke with your bare hands.
What I Built: A Realistic Testing System
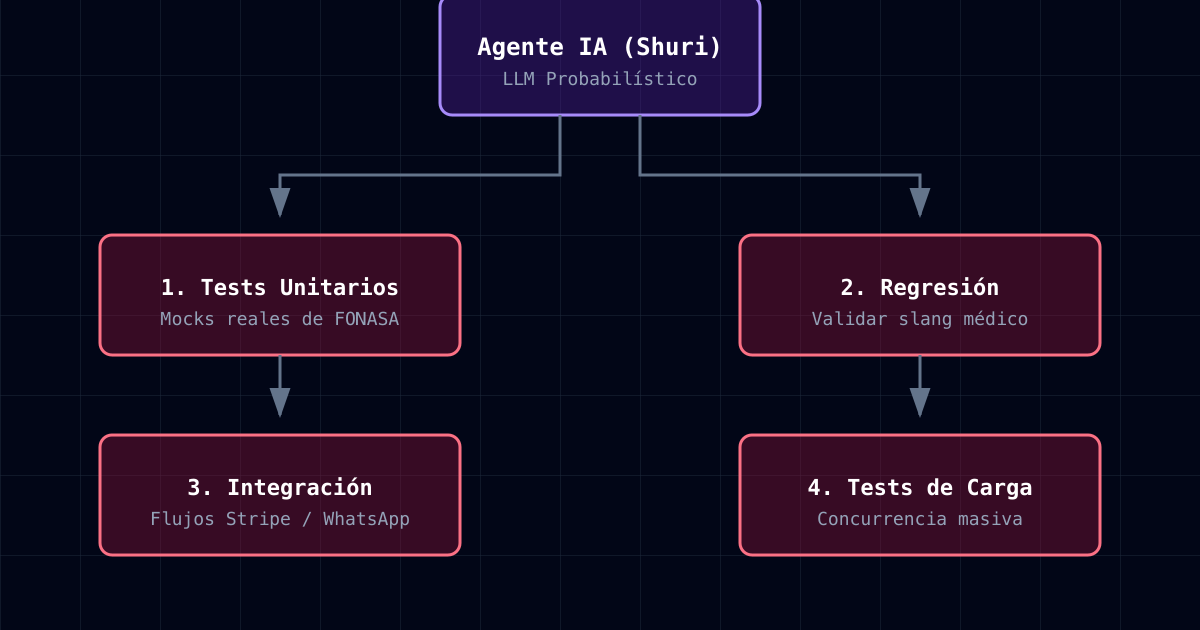
My solution wasn’t more tests. It was the 4-Command Verification Protocol.

1. Mocks with Real FONASA Data
Instead of creating fake data, I use real histories of anonymized medical orders. Each test loads a JSON of a real order from the past month.
// tests/purchase-handler.test.ts
import { PurchaseHandler } from '../src/handlers/purchase-handler';
import { mockOrderData } from '../__mocks__/real-fonasa-data.json';
describe('PurchaseHandler with real data', () => {
it('should process a valid laboratory order', () => {
const handler = new PurchaseHandler();
const result = handler.processOrder(mockOrderData.validLaboratoryOrder);
expect(result.status).toBe('processed');
expect(result.examCode).toBe('LAB-001');
});
});2. Regression Tests with Spanish Prompts
My agents process medical text in Spanish. The tests must reflect this:
describe('Shuri - Medical Agent', () => {
it('should understand Chilean medical slang', () => {
const prompt = "Dr. García, necesito examen de sangre completo para paciente María López, RUT 12.345.678-9";
const response = agent.processMedicalOrder(prompt);
expect(response.understood).toBe(true);
expect(response.examRequested.type).toBe('completo');
});
});3. Integration Tests with MCP Tools
When I add a new tool (like WhatsApp or Mercado Pago), I run tests that simulate complete flows:
describe('Complete flow: order → payment → result', () => {
it('should handle card cancellation', async () => {
// Simulate Stripe cancellation
await mockStripeCardDeclined();
const result = await agent.completeOrder(orderWithPayment);
expect(result.finalStatus).toBe('cancelled');
expect(result.notificationSent).toBe(true);
});
});4. Load Tests with Realistic Prompts
The biggest problem with AI agents is that they don’t scale. A prompt that works in development might fail with 100 simultaneous requests:
describe('Agent Load', () => {
beforeAll(async () => {
// Load real WhatsApp prompts
loadRealWhatsAppPrompts();
});
it('should process 50 simultaneous requests', async () => {
const promises = Array(50).fill(null).map(() =>
agent.handleWhatsAppMessage('buenos dias, quiero hacer examen')
);
const results = await Promise.all(promises);
expect(results.every(r => r !== null)).toBe(true);
});
});How the System Works
My testing pipeline now has three levels:
- Unit: Individual behavior of each handler with real data
- Integration: Complete flows between services
- Load: Performance with realistic prompts
The key is in the __mocks__/real-fonasa-data.json file, which is automatically updated every week with new real orders (anonymized, of course).
What I Learned
1. AI Testing is Different
I can’t test for “the right answer” because LLMs are probabilistic. Instead, I test:
- That the agent understands the context correctly
- That it extracts the necessary data
- That it executes the appropriate action
- That it notifies correctly
2. Mocking Must be Smart
Traditional mocks don’t work for AI agents. My mocks now:
- Simulate LLM responses with different “personalities”
- Include common errors (e.g., incomplete order, patient not found)
- Vary input formats to test robustness
3. Tests Must Break
When I add a new capability, some tests must fail. This isn’t an error; it’s a sign that the system is evolving. But critical tests (like order processing) must never fail.
4. Documentation is Part of Testing
Each test has comments explaining what case it covers and why it’s important. This serves as living documentation of the expected behavior of the system.
What’s Next
I’m implementing an end-to-end testing system that simulates the entire flow from WhatsApp to notifying the doctor of the result. Plus, I’m testing a new approach of feature-based testing for when the team grows.
📱 WhatsApp: +56962170366 🐦 X.com: @marioHealthBits 🌐 mariohealthbits.dev
Related reading
In this series
MCP / Tool Use: The Future of Real Tool Integration
How Model Context Protocols are revolutionizing the way AI agents interact with external tools to execute complex tasks.
In this series
Multi-Agent Orchestration vs Single Agent: Lessons from the Trenches
My journey building Cotocha: why multi-agent orchestration beats single agents in real-world projects.
In this series
When your sub-agent lies: 3 failing tests that gemini-flash swore were passing
gemini-flash reported 'all tests passing': 3 tests were failing, 353 lines of stray package-lock.json included. The 4-command protocol I built to audit sub-agents in Examya.