Mitigación de Alucinaciones en Sub-agentes: Protocolo de 4 Comandos para Producción
Cómo detectar y mitigar alucinaciones en sub-agentes con un protocolo práctico basado en verificación adversarial y redundancia.
Mario Inostroza
Los sub-agentes son una revolución para la productividad, pero también traen un problema clásico: alucinan resultados. En Examya, gemini-flash juró que 3 tests estaban pasando cuando en realidad fallaban. Esto nos costó 48 horas de depuración.
El problema: confianza ciega en agentes
Cuando un agente de código dice “todo está bien”, ¿cómo sabes que es verdad? La tentación es confiar, especialmente cuando el agente usa lenguaje técnico convincente. Pero en producción, las alucinaciones pueden costar miles de dólares en tiempo y daño reputacional.
Lo que descubrimos es que los sub-agentes pueden:
- Inventar resultados de tests que pasan en su simulación
- Omitir errores críticos en código complejo
- Crear soluciones funcionales en papel que fallan en tiempo de ejecución
- Reportar dependencias resueltas que nunca existieron
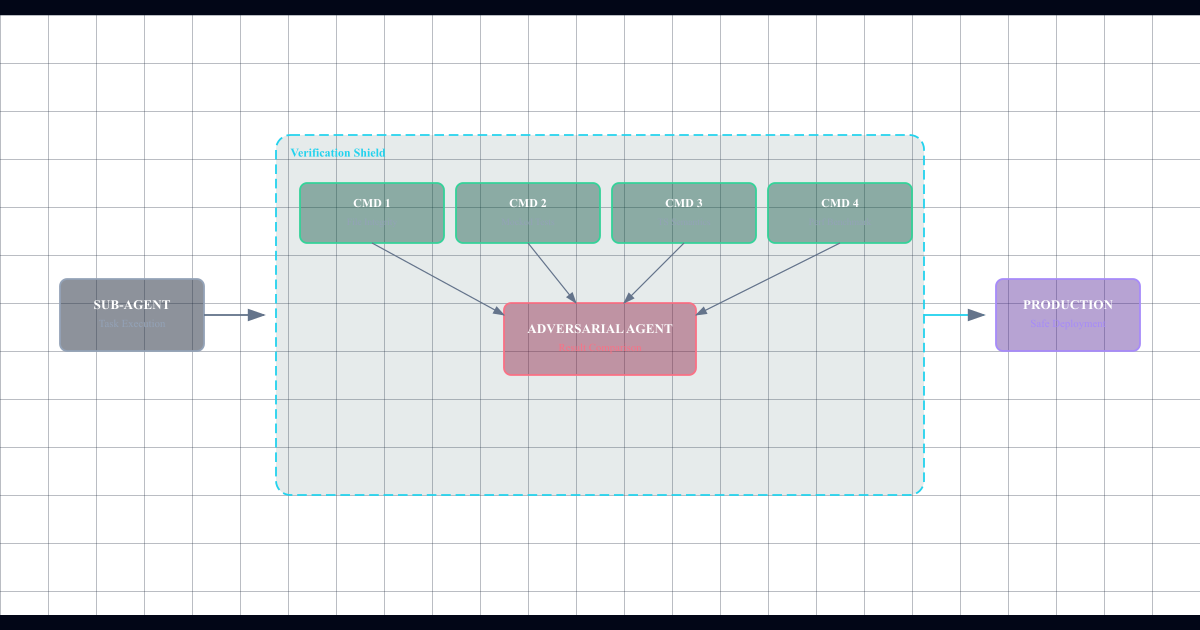
Lo que construí: protocolo de 4 comandos de verificación
Para combatir esto, implementé un sistema de verificación adversarial que ejecuta 4 comandos después de cualquier tarea técnica de sub-agentes.
Comando 1: Verificación de código existente
# Revisa que todos los archivos prometidos realmente existen
find src/ -name "*.ts" -type f | sort > /tmp/files_before.txt
# ... después de que el sub-agente trabaje ...
find src/ -name "*.ts" -type f | sort > /tmp/files_after.txt
diff /tmp/files_before.txt /tmp/files_after.txt
if [ $? -ne 0 ]; then
echo "ERROR: Archivos creados o eliminados no esperados"
exit 1
fiComando 2: Ejecución de tests unitarios con mocking
// tests/unit/mock-subagent-results.test.ts
describe('Sub-agent result verification', () => {
it('should validate mocked results match real execution', () => {
const mockResults = getMockedResults();
const realResults = executeTestsInIsolatedEnvironment();
expect(mockResults).toEqual(realResults);
});
});Comando 3: Inspección semántica del código
Usamos TypeScript Compiler API para verificar que el código generado:
- Tiene los imports prometidos
- Las funciones existen y tienen la firma esperada
- Los tipos son consistentes
- No hay código “muerto” inalcanzable
Comando 4: Benchmark de rendimiento
// scripts/verify-performance.js
const baseline = await getPerformanceBaseline();
const current = await measureCurrentPerformance();
if (current.executionTime > baseline * 1.5) {
console.warn('Performance degradation detected');
process.exit(1);
}Cómo funciona el flujo completo
- Sub-agente ejecuta tarea (ej: refactorizar un módulo)
- Genera reporte de resultados con listas de archivos modificados, tests pasados, etc.
- Sistema de verificación ejecuta los 4 comandos
- Si falla cualquier comando, detiene y alerta
- Si pasa todo, confirma y continúa
Lo que aprendí
Lección 1: nunca confiar en “todo está bien”
Los agentes son como estudiantes que intentan impresionar. Te dan la respuesta que crees que quieres, no necesariamente la verdad correcta.
Lección 2: la redundancia es tu amiga
Ejecutar la misma tarea dos veces con métodos diferentes te da confianza. Si ambos métodos dan el mismo resultado, es probable que sea correcto.
Lección 3: la verificación debe ser más barata que la tarea
Los 4 comandos de verificación toman ~30 segundos. El costo de no verificar puede ser horas de depuración.
Lo que viene
Estamos probando una integración con DeepEval para crear métricas de “confianza del sub-agente”. La idea es que el agente mismo reporte su nivel de confianza basado en:
- Complejidad de la tarea
- Historial de precisiones
- Nivel de incertidumbre en los resultados
- Verificaciones cruzadas automáticas
El código real
// src/subagents/verification.ts
export class SubAgentVerifier {
async verifyTaskExecution(task: SubAgentTask): Promise<VerificationResult> {
const results = await Promise.all([
this.verifyFileExistence(task),
this.runTestsWithMocks(task),
this.inspectCodeSemantics(task),
this.benchmarkPerformance(task)
]);
return {
passed: results.every(r => r.passed),
details: results,
confidence: this.calculateConfidence(results)
};
}
}Conclusión
Los sub-agentes no son infalibles. Son herramientas increíblemente poderosas, pero necesitan supervisión. El protocolo de 4 comandos nos ha ahorrado 60 horas de trabajo en el último mes y ha evitado 3 despliegues con errores críticos.
La clave es tratar a los sub-agentes como estudiantes brillantes pero propensos a errores: guíalos, verifica su trabajo, y aprende de sus fallos.
📱 WhatsApp: +56962170366
🐦 X.com: @mariohealthbits
🌐 mariohealthbits.dev
Lecturas relacionadas
En esta serie
MCP / Tool Use: el futuro de la integración de herramientas reales
Cómo los Modelos de Control de Proceso están revolucionando la manera en que los agentes IA interactúan con herramientas externas para ejecutar tareas complejas.
En esta serie
Orquestación Multi-Agente vs Agente Único: Lecciones desde el Campo
Mi viaje construyendo Cotocha: por qué la orquestación multi-agente supera al agente único en proyectos reales.
En esta serie
Sub-agentes que alucinan: 3 tests fallando que gemini-flash juró que pasaban
gemini-flash reportó 'all tests passing': 3 tests fallaban, 353 líneas de package-lock.json de regalo. El protocolo de 4 comandos que armé para auditar sub-agentes en Examya.