Democratizando el acceso a FONASA MLE: Datos abiertos y un servidor MCP
Cómo convertimos el catálogo de exámenes FONASA en una herramienta para agentes de IA con un servidor MCP y datos normalizados a 7 dígitos.
Mario Inostroza
En Chile, el catálogo de Modalidad Libre Elección (MLE) de FONASA es la “fuente de verdad” para miles de prestaciones médicas. Sin embargo, acceder a él de forma programática ha sido históricamente un infierno de planillas Excel inconsistentes y códigos truncados.
Hoy publicamos fonasa-mle-open, un proyecto open source que limpia estos datos y los expone mediante un servidor MCP para que cualquier agente de IA pueda entender el sistema de salud chileno.
El problema de las planillas “vivas”
Cada marzo, FONASA publica sus anexos. Pero aquí está el gotcha: el archivo de 2025 no se parece en nada al de 2026. Uno usa sharedStrings.xml en su estructura interna, el otro usa strings in-line. Uno tiene 3 hojas, el otro solo 1.
Si intentas parsearlos de forma ingenua, pierdes datos o, peor aún, destruyes los precios.
Lo que construimos: Normalización quirúrgica
Implementamos un extractor en Python que normaliza cada prestación a su código canónico de 7 dígitos (Grupo + Subgrupo + Item). Sin esto, la interoperabilidad es imposible.
// Ejemplo de búsqueda robusta en el servidor MCP
const codeQuery = query.replace(/\D/g, "").padStart(7, "0");
// Ahora "301045" siempre encontrará el "0301045" (Hemograma)El Gotcha: La trampa de los decimales de Excel
Un bug real que enfrentamos: Excel a veces exporta 1680 como 1680.0. En la lógica de precios chilena, donde el punto suele ser separador de miles (1.680), una heurística simple puede terminar convirtiendo un examen de $1.680 en uno de $16.800.
Lo resolvimos con una limpieza por regex y un redondeo estricto antes de la conversión a entero.
Seguridad y Robustez
No nos quedamos solo en los datos. Aplicamos un Judgment Day (revisión adversarial) al código y surgieron temas críticos:
- Protección XXE: El parser de XML ahora está bloqueado contra entidades externas para evitar exfiltración de datos.
- Búsqueda Híbrida: El servidor MCP ahora maneja búsquedas parciales de códigos ignorando ceros a la izquierda, ideal para cuando un usuario tipea rápido.
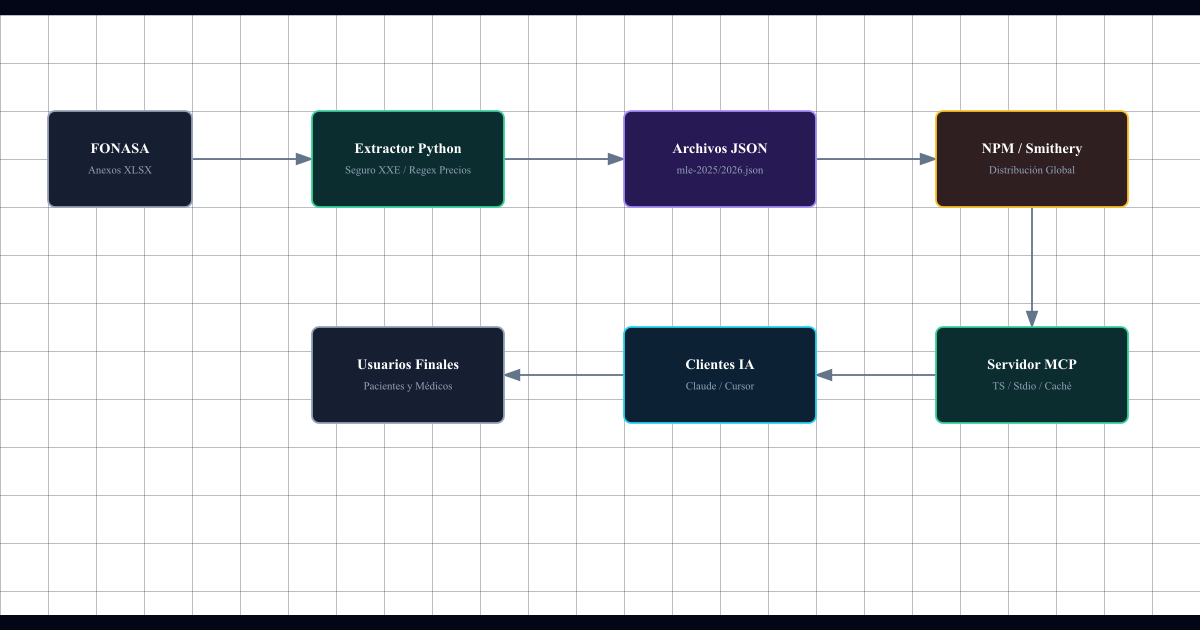
Arquitectura del Sistema
Para asegurar la integridad de los datos, diseñamos un pipeline que va desde el Excel oficial hasta el agente de IA:
¿Por qué un servidor MCP?
Los agentes de IA (como Claude) ahora pueden “aprender” de salud chilena en tiempo real. Al conectar este servidor a Claude Desktop, el modelo ya no alucina precios: consulta la fuente de verdad.
Ya disponible para la comunidad
El proyecto ya es una realidad y puedes usarlo de tres formas:
- NPM: Ejecútalo directamente con
npx @mariohealthbits/fonasa-mle-open. - Smithery.ai: Encuéntralo en el catálogo oficial de Smithery.
- GitHub: Revisa el código y los datos en marioSoftmedic/fonasa-mle-open.
Lo que viene
El próximo paso es automatizar la extracción con un GitHub Action para marzo de 2027, asegurando que los datos siempre estén al día.
📱 WhatsApp: +56962170366 🐦 X.com: @mariohealthbits 🌐 mariohealthbits.dev
Lecturas relacionadas
Por temas similares
Crowdsourcing de precios médicos: cómo Examya construye transparencia de costos capa por capa
Arquitectura real de las 3 capas de inteligencia de precios en Examya: datos FONASA, crowdsourcing de usuarios y generación de órdenes desde WhatsApp. Con código, decisiones de diseño y bugs reales.
Por temas similares
Mi stack B2B: Cómo uso NotebookLM y Obsidian para cerrar negocios en salud
Vender software clínico requiere procesar horas de reuniones y PDFs densos. Así armé un workflow con IA para convertir documentos en propuestas letales.
Por temas similares
La IA clínica falla por el dato, no por el modelo
Un modelo clínico puede sonar correcto y fallar igual si recibe PDFs, texto libre y resultados sin trazabilidad. El problema empieza antes del prompt.