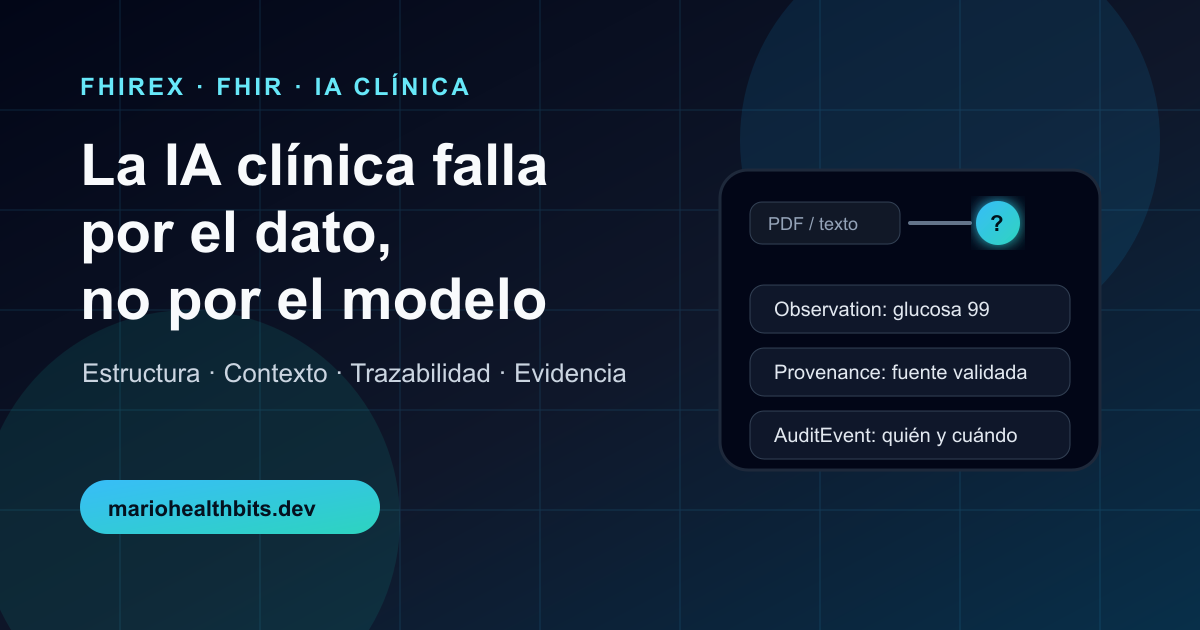
La IA clínica falla por el dato, no por el modelo
Un modelo clínico puede sonar correcto y fallar igual si recibe PDFs, texto libre y resultados sin trazabilidad. El problema empieza antes del prompt.
Mario Inostroza
La pregunta más común cuando un equipo de salud empieza a explorar IA clínica es: “¿qué modelo usamos?”.
GPT-4. Claude. Gemini. Un modelo local. Un modelo médico especializado. Un ensemble. Un agente.
La pregunta importa, pero llega tarde.
En salud, muchas veces la IA no falla porque el modelo sea malo. Falla porque el dato que le entregamos llega sin estructura, sin contexto y sin trazabilidad suficiente para tomar una decisión responsable.
Un LLM puede leer un PDF. Puede resumir una ficha. Puede explicar un resultado. Incluso puede sonar razonable mientras lo hace.
Ese es precisamente el riesgo.
El problema no empieza en el prompt
Cuando un sistema de IA clínica responde mal, es tentador mirar primero el prompt o el modelo.
“Hay que mejorar las instrucciones”.
“Hay que cambiar de modelo”.
“Hay que agregar más contexto”.
A veces eso ayuda. Pero en salud hay una capa anterior: el dato clínico que entra al sistema.
Si el modelo recibe un resultado de laboratorio como PDF plano, no sabe por sí solo qué parte es valor, qué parte es unidad, qué parte es rango de referencia, qué parte es comentario técnico y qué parte corresponde al paciente correcto.
Puede inferirlo. Pero inferir no es lo mismo que saber.
Y en salud esa diferencia importa.
Texto libre no es contexto clínico
Un texto largo puede contener mucha información y seguir siendo mal contexto para IA.
Una ficha clínica puede decir “paciente con control pendiente”, pero no necesariamente explicitar qué evento generó ese pendiente, qué profesional lo indicó, si la orden está vigente o si el resultado ya fue validado.
Un informe de laboratorio puede mostrar glucosa, colesterol o hemoglobina, pero si el dato llega como imagen o texto plano, el sistema debe reconstruir:
- nombre del examen;
- unidad;
- rango de referencia;
- fecha de toma de muestra;
- fecha de validación;
- profesional o sistema que emitió el resultado;
- relación con la orden original;
- estado del informe.
Ese trabajo de reconstrucción puede funcionar en una demo. Pero no debería ser la base de un flujo clínico confiable.
El problema no es que el modelo no pueda leer. El problema es que le estamos pidiendo que adivine estructura clínica que debería venir explícita.
Lo que un modelo necesita para ser útil
Una IA clínica no necesita solo más tokens. Necesita mejor contexto.
Para que una respuesta sea auditable, el sistema debería poder responder preguntas como estas:
| Pregunta | Por qué importa |
|---|---|
| ¿Qué dato usó el modelo? | Permite revisar si la respuesta se basó en la fuente correcta. |
| ¿De dónde viene ese dato? | Distingue resultado validado, texto libre, transcripción o inferencia. |
| ¿Cuándo se generó? | En clínica, la fecha cambia el significado del dato. |
| ¿Quién lo validó? | No es lo mismo un resultado preliminar que uno validado. |
| ¿Con qué unidad y rango se interpreta? | Evita comparar valores fuera de contexto. |
| ¿Qué parte fue procesada por IA? | Permite auditar errores y responsabilidades. |
Si el sistema no puede responder eso, no estamos frente a IA clínica lista para producción. Estamos frente a una interfaz convincente sobre datos débiles.
Donde FHIR cambia la conversación
FHIR no hace que la IA sea inteligente. Tampoco reemplaza al razonamiento clínico.
Lo que puede hacer es ordenar el contexto que la IA consume.
En vez de pasarle al modelo un bloque gigante de texto, podemos representar eventos clínicos como recursos con relaciones explícitas:
Lecturas relacionadas
Recomendado
Human-in-the-loop no basta: cómo diseño supervisión real para IA médica
Supervisar IA médica no es poner un médico mirando. Requiere autoridad, trazabilidad, escalamiento, monitoreo de drift y evidencia auditable.
Recomendado
Fhirex by Examya: pilotos FHIR sin tocar producción
Por qué lanzamos fhirex.examya.cl: pilotos FHIR/Core-CL con datos sintéticos, evidencia técnica y revisión TI antes de producción.
Recomendado
Chile obliga a interoperar fichas clínicas: por qué esto cambia todo para la salud digital
La Ley 21.668 obliga a todos los prestadores de salud en Chile a interoperar sus fichas clínicas. Analizo qué significa esto técnicamente, qué estándares vienen (FHIR, SNOMED CT, AIToF), y cómo Examya se está preparando para este nuevo mercado obligatorio.