Clinical AI Fails Because of Data, Not the Model
A clinical model can sound correct and still fail if it receives PDFs, free text and lab results without traceability. The problem starts before the prompt.
Mario Inostroza
The most common question when a healthcare team starts exploring clinical AI is: “Which model should we use?”
GPT-4. Claude. Gemini. A local model. A medical model. An ensemble. An agent.
The question matters, but it comes late.
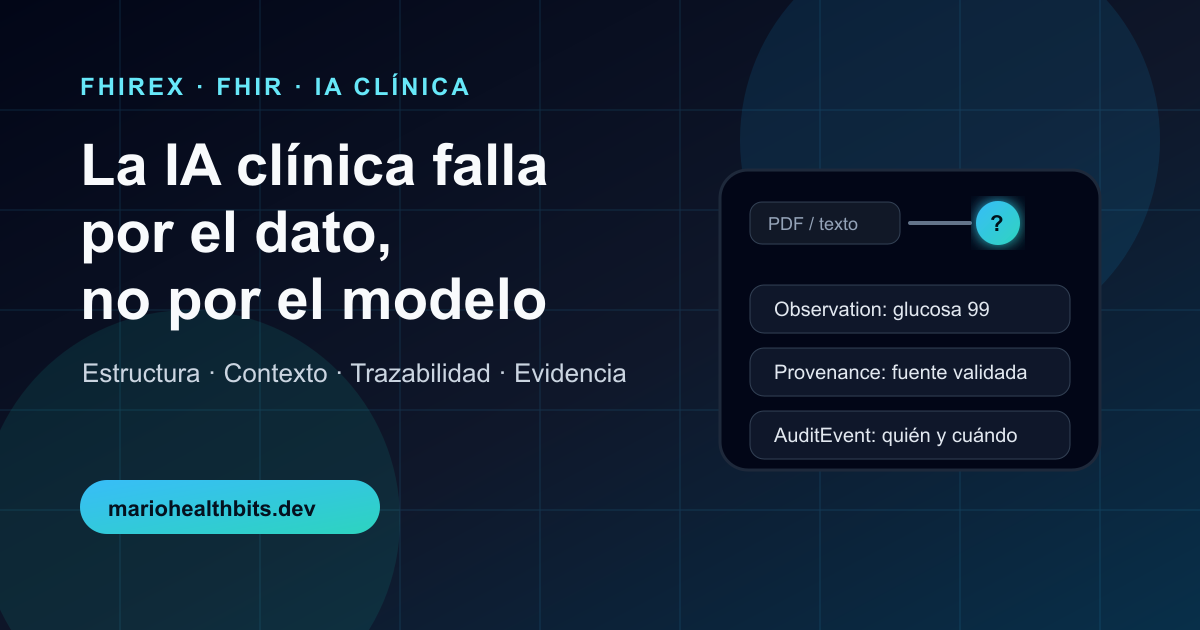
In healthcare, AI often does not fail because the model is bad. It fails because the data we give it has no structure, no context and no traceability.
An LLM can read a PDF. It can summarize a medical record. It can explain a lab result. It can even sound reasonable while doing it.
That is exactly the risk.
The problem does not start in the prompt
When a clinical AI system gives a bad answer, it is tempting to look first at the prompt or the model.
“Improve the instructions.”
“Switch models.”
“Add more context.”
Sometimes that helps. But healthcare has a layer before that: the clinical data entering the system.
If the model receives a lab result as a flat PDF, it does not inherently know which part is the value, which part is the unit, which part is the reference range, which part is the technical comment and whether it belongs to the correct patient.
It can infer. But inferring is not the same as knowing.
And in healthcare, that difference matters.
Free text is not clinical context
A long text can contain a lot of information and still be poor context for AI.
A medical record can say “patient pending follow-up” without making explicit which event created that pending task, who ordered it, whether the order is still active or whether the result has already been validated.
A lab report can show glucose, cholesterol or hemoglobin, but if the data arrives as an image or plain text, the system has to reconstruct:
- test name;
- unit;
- reference range;
- sample date;
- validation date;
- professional or system that issued the result;
- relationship with the original order;
- report status.
That reconstruction may work in a demo. It should not be the foundation for a reliable clinical workflow.
The issue is not that the model cannot read. The issue is that we are asking it to guess clinical structure that should be explicit.
What a model needs to be useful
Clinical AI does not just need more tokens. It needs better context.
For an answer to be auditable, the system should be able to answer:
| Question | Why it matters |
|---|---|
| What data did the model use? | It lets the team review whether the answer used the correct source. |
| Where did that data come from? | It separates validated results, free text, transcription and inference. |
| When was it generated? | In clinical work, time changes the meaning of data. |
| Who validated it? | A preliminary result is not the same as a validated result. |
| Which unit and range apply? | It prevents comparing values out of context. |
| Which part was processed by AI? | It supports error review and accountability. |
If the system cannot answer that, it is not production-ready clinical AI. It is a convincing interface on top of weak data.
Where FHIR changes the conversation
FHIR does not make AI intelligent. It does not replace clinical reasoning either.
What it can do is organize the context that AI consumes.
Instead of sending the model a giant text block, we can represent clinical events as resources with explicit relationships:
Related reading
Recommended
Human-in-the-loop is not enough: designing real oversight for medical AI
Medical AI oversight is not a doctor watching a screen. It requires authority, traceability, escalation, drift monitoring, and auditable evidence.
Recommended
Fhirex by Examya: FHIR pilots without touching production
Why we launched fhirex.examya.cl: FHIR/Core-CL pilots with synthetic data, technical evidence, and IT review before production.
Recommended
Chile now requires clinical record interoperability: why this changes everything for digital health
Law 21.668 mandates all healthcare providers in Chile to make clinical records interoperable. I analyze what this means technically, which standards are coming (FHIR, SNOMED CT, AIToF), and how Examya is preparing for this newly mandatory market.