Por qué el índice de tu vault importa más que la cantidad de notas
Acumular notas no escala con IA. Cómo un _INDEX.md se volvió el contrato vital para que mis agentes no destruyan el blog.
Mario Inostroza
Hay una trampa muy común cuando empiezas a armar tu sistema de conocimiento (PKM): la métrica de vanidad de cuántas notas tienes. Al principio, ver el gráfico de red de Obsidian llenándose de puntitos te hace sentir súper productivo.
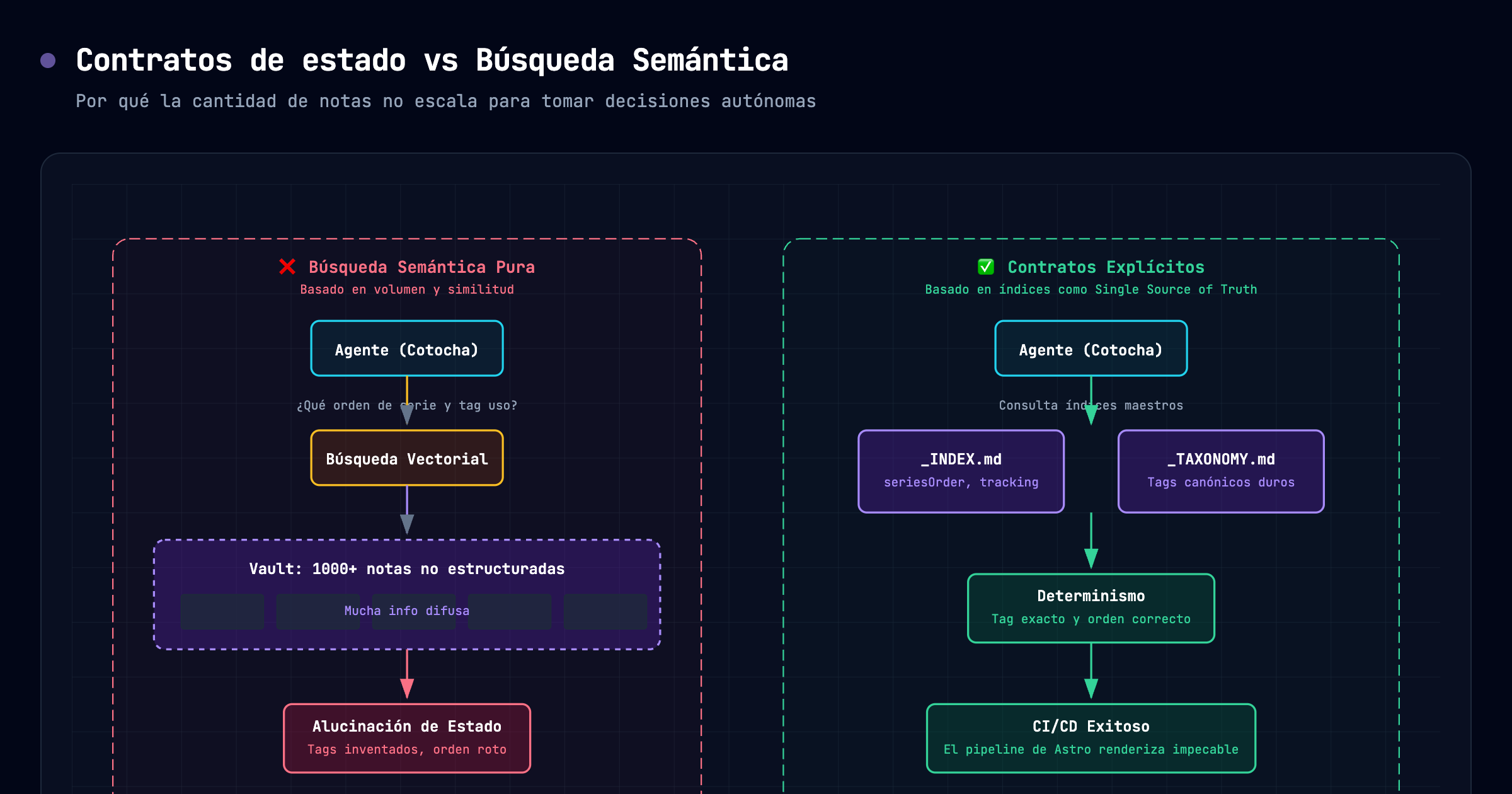
Pero cuando empiezas a conectar agentes de IA a tu vault, la cantidad de notas se vuelve un problema. La búsqueda semántica y los embeddings son bacanes, pero fallan cuando el agente necesita tomar decisiones de estado duro, como “¿qué número de capítulo le toca a este post?” o “¿este tag existe en el sistema?”.
Lo que nadie te cuenta de la indexación
Un LLM leyendo mil notas sueltas para deducir el contexto general es caro, lento y propenso a alucinar. Va a encontrar tres notas que hablan de “Agentes” y decidirá que el próximo post es el número 4, ignorando que el post número 4 ya está programado en otra carpeta.
La búsqueda vectorial encuentra similitudes, pero no entiende de contratos de estado. Si un agente no tiene un lugar centralizado donde ver la taxonomía aprobada, va a empezar a inventar tags (“IA”, “Inteligencia Artificial”, “AI”, “Artificial_Intelligence”) y va a romper el pipeline de CI/CD del blog de inmediato.
Los datos reales: el _INDEX.md
En mi flujo actual, el agente Cotocha publica automáticamente en mariohealthbits.dev. Para que esto funcione sin intervención humana diaria, tuve que implementar dos archivos vitales en la raíz de mi carpeta de blog en Obsidian: _INDEX.md y _TAXONOMY.md.
Antes de generar una sola línea de código o texto, Cotocha tiene la instrucción estricta de leer esos dos archivos. No lee las 200 notas del blog, lee el índice.
Lo que construí: El contrato explícito
El _INDEX.md no es solo una tabla de contenidos, es un registro de estado. Mantiene un snapshot de qué series están activas, qué número le toca a la siguiente publicación (Próximo orden libre) y qué temas ya se cubrieron para evitar repetición.
## Series activas
| Series slug | Tema | Próximo orden libre |
| ----------------- | ----------------------------------- | ------------------- |
| `examya` | Construcción de Examya (agente) | 8 |
| `cerebro-digital` | Engram + Obsidian + Cotocha | 7 |Por su parte, _TAXONOMY.md es el límite rígido. Si Cotocha intenta usar un tag que no está en esa lista exacta, la automatización falla intencionalmente antes de llegar a producción.
El gotcha: La IA necesita límites, no solo contexto
El gran aprendizaje de automatizar la publicación es que los LLMs son máquinas probabilísticas. Si quieres que operen sistemas determinísticos (como el enrutamiento de Astro o un build de Vercel), tienes que acorralarlos con contratos explícitos.
Acumular notas sueltas sirve para el brainstorming humano, pero para orquestar agentes, un buen índice mantenido como fuente de verdad le gana por paliza a mil notas sin estructura.
Zoom out
Esto aplica mucho más allá de un blog. Si estás construyendo sistemas RAG corporativos, depender exclusivamente de la similitud del vector va a generar inconsistencias en reglas de negocio. Siempre vas a necesitar “índices” o tablas maestras de estado que el LLM pueda consultar para tomar decisiones discretas.
Lo que viene
El siguiente paso es hacer que Cotocha no solo lea el _INDEX.md, sino que sea capaz de reescribirlo y hacerle commit de vuelta al repositorio cada vez que publica algo nuevo, cerrando el ciclo de automatización sin que yo tenga que tocar un solo archivo.
📱 WhatsApp: +56962170366 🐦 X.com: @mariohealthbits 🌐 mariohealthbits.dev
Lecturas relacionadas
Recomendado
Mi cerebro digital: cómo conecté memoria, conocimiento y publicación automática
Cómo construí un sistema que extrae memorias de IA desde un VPS, las organiza en Obsidian al estilo Karpathy, y publica artículos automáticamente en el blog, X.com y LinkedIn.
Recomendado
El bug invisible de mi segundo cerebro: cuando el VPS escribía en un vault que nadie leía
Cotocha editaba el vault en el VPS, pero nada llegaba a mi Mac. La lección: sincronizar agentes requiere contratos verificables, no suposiciones.
En esta serie
Cotocha: el orquestador de agentes que corre mi vida desde un VPS
Cómo construí un sistema de agentes IA que maneja infraestructura, alertas, base de datos y blogging desde un servidor en Alemania. Sin intermediarios, sin dashboards bonitos.