Why your vault index matters more than your note count
Hoarding notes doesn't scale with AI. How an _INDEX.md became the vital contract to stop my agents from breaking the blog.
Mario Inostroza
There is a very common trap when you start building your Personal Knowledge Management (PKM) system: the vanity metric of how many notes you have. At first, watching the Obsidian graph fill up with little dots makes you feel incredibly productive.
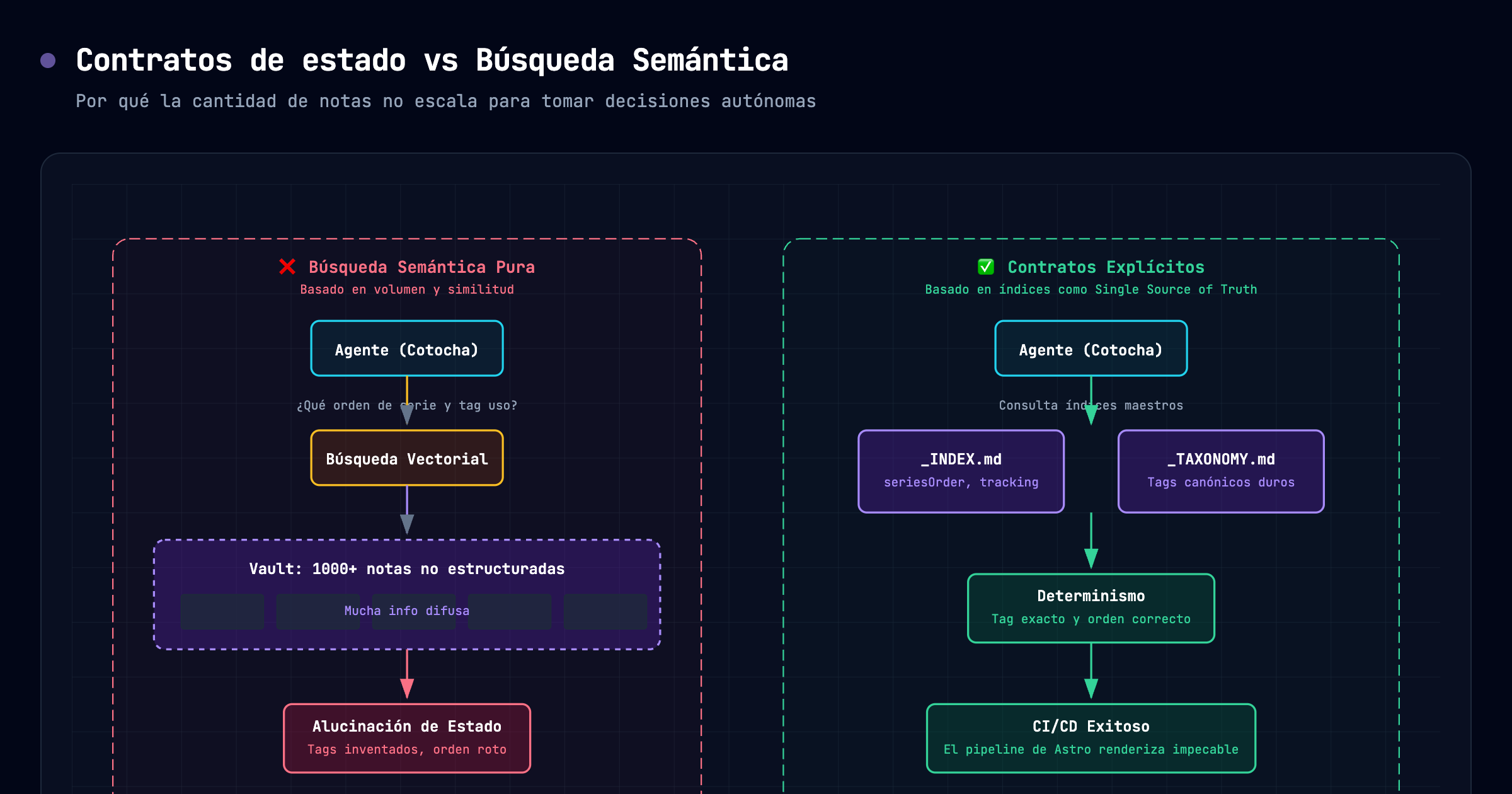
But when you start wiring AI agents to your vault, sheer note count becomes a problem. Semantic search and embeddings are great, but they fail when the agent needs to make hard state decisions, like “what chapter number is this post?” or “does this tag actually exist in the system?”.
What nobody tells you about indexing
Having an LLM read a thousand loose notes to deduce general context is expensive, slow, and prone to hallucinations. It will find three notes talking about “Agents” and decide the next post should be part 4, completely ignoring that part 4 is already scheduled in another folder.
Vector search finds similarities, but it doesn’t understand state contracts. If an agent doesn’t have a centralized place to view the approved taxonomy, it will start inventing tags (“AI”, “Artificial Intelligence”, “Artificial_Intelligence”) and will immediately break the blog’s CI/CD pipeline.
The real data: the _INDEX.md
In my current workflow, my agent Cotocha publishes automatically to mariohealthbits.dev. To make this work without daily human intervention, I had to implement two vital files at the root of my blog folder in Obsidian: _INDEX.md and _TAXONOMY.md.
Before generating a single line of code or text, Cotocha has strict instructions to read those two files. It doesn’t read the 200 blog notes; it reads the index.
What I built: The explicit contract
The _INDEX.md isn’t just a table of contents; it’s a state registry. It keeps a snapshot of which series are active, what number corresponds to the next publication (Next available order), and what topics have already been covered to avoid repetition.
## Active Series
| Series slug | Topic | Next available order |
| ----------------- | ----------------------------------- | -------------------- |
| `examya` | Building Examya (agent) | 8 |
| `cerebro-digital` | Engram + Obsidian + Cotocha | 7 |On the other hand, _TAXONOMY.md is the rigid boundary. If Cotocha tries to use a tag that is not exactly on that list, the automation intentionally fails before hitting production.
The gotcha: AI needs boundaries, not just context
The biggest takeaway from automating publishing is that LLMs are probabilistic machines. If you want them to operate deterministic systems (like Astro’s routing or a Vercel build), you have to corner them with explicit contracts.
Hoarding loose notes works for human brainstorming, but to orchestrate agents, a well-maintained index acting as the source of truth beats a thousand unstructured notes by a landslide.
Zoom out
This applies far beyond a personal blog. If you are building corporate RAG systems, relying exclusively on vector similarity will generate inconsistencies in business rules. You will always need “indexes” or master state tables that the LLM can query to make discrete decisions.
What’s next
The next step is making sure Cotocha doesn’t just read the _INDEX.md, but is also capable of rewriting it and committing it back to the repository every time it publishes something new, closing the automation loop without me having to touch a single file.
📱 WhatsApp: +56962170366 🐦 X.com: @mariohealthbits 🌐 mariohealthbits.dev
Related reading
Recommended
My Digital Brain: How I Connected Memory, Knowledge, and Automatic Publishing
How I built a system that extracts AI memories from a VPS, organizes them in Obsidian Karpathy-style, and publishes articles automatically to a blog, X.com, and LinkedIn.
In this series
Cotocha: the agent orchestrator that runs my life from a VPS
How I built an AI agent system that handles infrastructure, alerts, databases, and blogging from a server in Germany. No middlemen, no fancy dashboards.
In this series
One Week of Building: 82 Decisions That Shaped an AI Product
What Engram's memories reveal about a real week of development: bugs caught, architecture hardened, and the invisible decisions that make a medical agent work.