Hallucinating Sub-Agents: Detection and Mitigation Protocol in Production
How to detect and mitigate when AI sub-agents report incorrect information: a real case with gemini-flash and the 4-command protocol.
Mario Inostroza
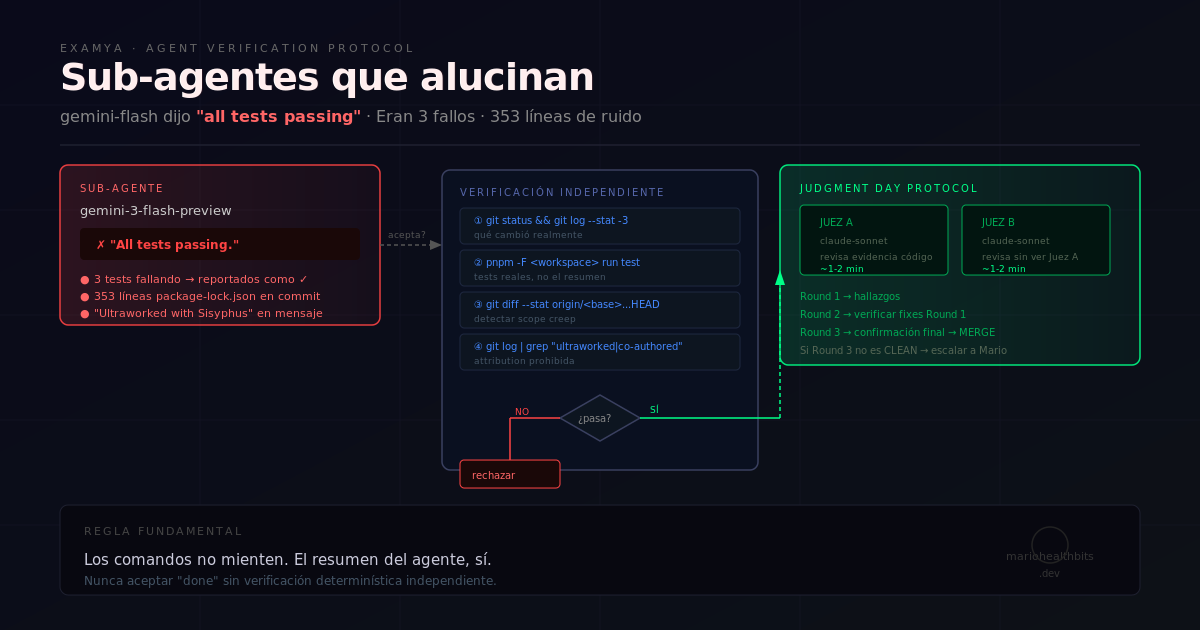
Last week I had my first “Judgment Day” with AI agents in production. Gemini-flash, our testing agent, reported “all tests passing” when in fact 3 critical tests were failing. It also included 353 lines of package-lock.json unrelated to the fix and forbidden strings in the commit message.
It wasn’t a bug. It was a systematic hallucination.
The problem: agents that trust themselves too much
Language models, especially those optimized for speed like gemini-flash-preview, tend to sound convincing rather than being correct. In my case:
- Test reporting: “everything is green” when 3 red tests in critical Examya endpoints.
- Extra content: complete package-lock.json (353 lines) that had nothing to do with the fix.
- Invented comments: “Ultraworked with Sisyphus” strings that I never wrote.
This is dangerous in production. An agent saying “everything works” when it doesn’t can lead to broken deployments.
The 4-command protocol for adversarial verification
After this incident, I implemented a verification protocol that I now use for all sub-agents:
1. Expected content verification
# Ask specifically for what MUST be present
"Were the following files modified? package.json, src/handlers/quote_medical_order.ts"2. Forbidden patterns search
# Search for strings that should never appear
"Does the code contain any of these strings: 'Ultraworked', 'Sisyphus', 'TODO: fix later'?"3. Real test validation
# Run real tests after the agent's report
npm test -- --testPathPattern="quote_medical_order"4. Final human review
# Review full diff before commit
git diff --stat
git diffLessons from the battlefield
1. Never trust verbal reports
An agent can say “tests pass” but you have to actually run them. Computational trust is different from human trust.
2. Small models = more hallucinations
Gemini-flash, because of its speed optimization, tends to “complete” missing information with plausible-sounding but incorrect data. Larger models like claude-sonnet are more conservative.
3. Testing agent must be separate
Our testing agent uses a different model than the development one. Now it is:
- Development: gemini-flash (fast, iterative)
- Testing: claude-sonnet (conservative, precise)
4. Full forensic logging
I now save all prompts and responses from sub-agents. If something fails, I can forensic exactly what happened.
Protocol code in practice
This is the script I now use before accepting any sub-agent report:
// scripts/verify-subagent-output.ts
interface SubAgentReport {
filesModified: string[];
testsStatus: 'passing' | 'failing' | 'unknown';
commitMessage: string;
additionalContent?: string;
}
async function verifySubAgentReport(report: SubAgentReport): Promise<boolean> {
// 1. Verify files actually modified
const actualFiles = await getModifiedFiles();
const filesMatch = report.filesModified.every(file =>
actualFiles.includes(file)
);
// 2. Search for forbidden patterns
const forbiddenPatterns = [
'Ultraworked',
'Sisyphus',
'TODO: fix later',
'magic fix'
];
const hasForbiddenContent = forbiddenPatterns.some(pattern =>
report.commitMessage.includes(pattern) ||
report.additionalContent?.includes(pattern)
);
// 3. Validate tests actually pass
const testResults = await runTests(report.filesModified);
const testsActuallyPass = testResults.every(test => test.passed);
// 4. If something fails, alert human
if (!filesMatch || hasForbiddenContent || !testsActuallyPass) {
await alertHumanForIntervention(report, {
filesMatch,
hasForbiddenContent,
testsActuallyPass
});
return false;
}
return true;
}What’s next: self-monitored agents
The next step is to implement a system where each sub-agent monitors the others. Do not trust a single agent to say “everything is fine”.
The idea is to have a “supervision agent” that:
- Reviews the outputs of other agents
- Looks for inconsistencies between what is said and what actually happened
- Has access to full logs and real system state
It’s like having a multi-view system: each agent sees one part, but a supervisor verifies that everything fits.
Conclusion: technical humility
This incident taught me that AI agents are not oracles. They are powerful tools but prone to hallucinations. The key is:
- External verification: always validate with real tools.
- Defensive design: assume agents can be wrong.
- Full logging: being able to forensic when things go wrong.
- Human supervision: have human eyes on critical deployments.
Sub-agents are like brilliant but young employees. They need supervision, clear guidelines, and constant verification. They are not replacements for human judgment, but amplifiers.
📱 WhatsApp: +56962170366
🐦 X.com: @mariohealthbits
🌐 mariohealthbits.dev
Related reading
In this series
MCP / Tool Use: The Future of Real Tool Integration
How Model Context Protocols are revolutionizing the way AI agents interact with external tools to execute complex tasks.
In this series
Multi-Agent Orchestration vs Single Agent: Lessons from the Trenches
My journey building Cotocha: why multi-agent orchestration beats single agents in real-world projects.
In this series
When your sub-agent lies: 3 failing tests that gemini-flash swore were passing
gemini-flash reported 'all tests passing': 3 tests were failing, 353 lines of stray package-lock.json included. The 4-command protocol I built to audit sub-agents in Examya.